本文不会介绍cache的组织形式等基本内容,但也算不上什么"Advanced"。主要包含一些从硬件层面优化cache的手段。
优化cache的几种方法
pipeline caches
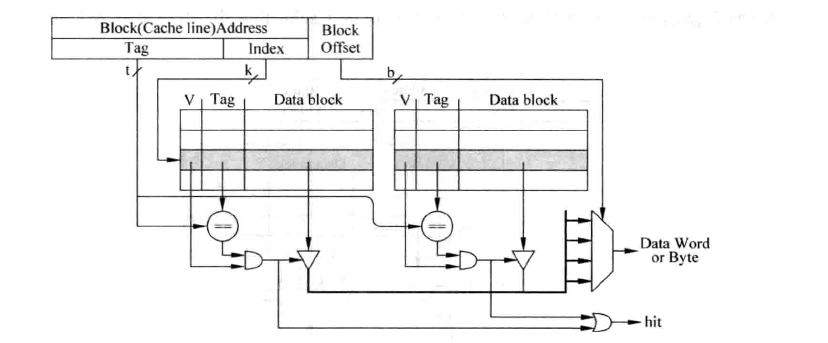
上图为教科书上经常出现的cache形式(2-way associative为例),它很精炼的解释了cache的实现。但也稍微引入了些“误导”:
- 图中
v、tag和data部分画在连续的一行上,仿佛硬件上他们就是同一块 SRAM 的不同bit - 图中识别
tag与data是并行完成的,这很好,某种意义上能降低时延;但我们经常遗忘一个事实,只有读cache的时候我们才能这么操作(或者说在写cache时,读取data block是没有意义的)
对于第一点,在实际的实现当中,tag和data部分都是分开放置的,tag一般是由一种叫CAM(Context-Addressable Memory)的材料构成。当然,这与pi不pipeline没什么关系;
读cache主要就两个部分:比较tag,获取data;我们暂且不考虑以pipeline的方式优化,那么serial的先比较tag再读data一定不如parallel的方式进行吗?当我们并行的读取tag和data的时候,我们会发现,读出来的data有可能没用(没有匹配的tag);并且,在n-way set associate cache中,我们会浪费的读出$n-1$个data项;这给我们什么启示呢?如果我们串行的读cache,那么我们可以在比较tag阶段就知道我们想要的数据在不在cache当中;更有意义的是,根据tag比较的结果,我们就知道哪一路的数据是需要被访问的(提前知道了在n-way中的哪一way),那么我们访问data block时,就无需多路选择器,直接访问指定的way,将其他way的data访问的使能信号置为无效,这种做法的优点在于有效减小功耗。
serial的做法肯定比parallel的延时要大,若这时访问cache处于处理器的critical path(关键路径)上,我们可以再将其进行流水线化。
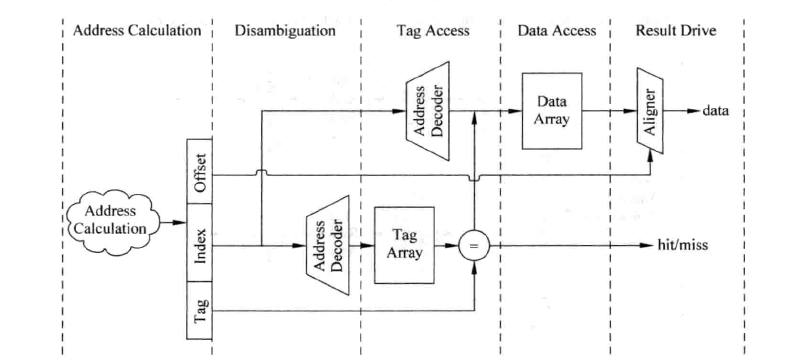
我们现在再来看看写cache时的情况:
写cache时,只有通过tag比较,确认要写的地址在cache中后,才可以写data SRAM,在主频较高的处理器中,这些操作很难在一个周期内完成,这也要求我们将其流水线化。下图为对cache进行写操作使用的流水线示意图:
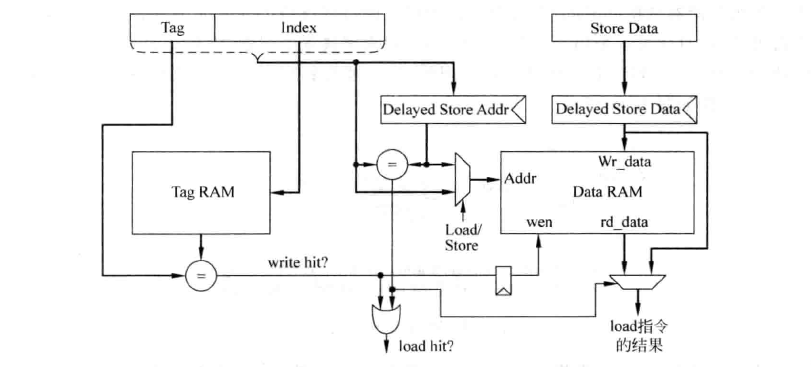
在上图的实现方式中,store第一个周期读取Tag并进行比较,根据比较的结果,在第二个周期选择是否将数据写到Data SRAM中。还需要注意的是,当执行load指令时,它想要的数据可能正好在store指令的流水线寄存器中(RAW的情况;上图中的DelayedStoreData寄存器),而不是来自于Data SRAM。因此需要一种机制检测这种情况,这需要将load指令所携带的地址和store指令的流水线寄存器(即DelayedStoreAddr寄存器)进行比较,如果相等,那么就将store指令的数据作为load指令的结果。
由此可以看出,对写D-Cache使用流水线之后,不仅增加了流水线本身的硬件,也带来了其他一些额外的硬件开销。其实。不仅在Cache中有这种现象,在处理器的其他部分增加流水线的级数,也会伴随着其他方面的硬件需求,因此过深的流水线带来的硬件复杂度是非常高的,就像Intel的Pentium 4处理器,并不会从过深的流水线中得到预想的好处。当然,cache的流水线化已经是一种广泛使用的用于降低latency的方法了。
write buffers
我愿称之为buffer of buffer,本来cache就起buffer的作用了,但我们再加一个buffer,如下图所示:
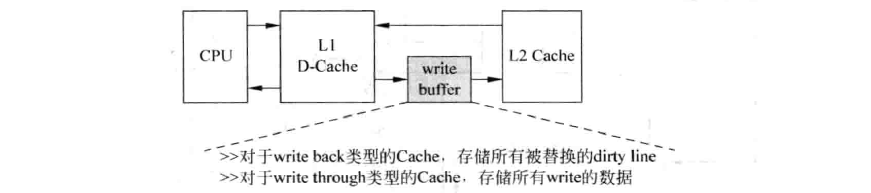 这和多一级的cache有什么不同呢?这是一个专门为写操作设计的buffer(注意:load也可能造成写操作)。原因在于我们知道写通常比读更慢,特别对于write-through来说;其次,当上层cache满后,需要先将dirty cache line写回下层cache,再读取下层cache中的数据。若下层cache只有一个读写端口,那么这种串行的过程导致D-Cache发生缺失的处理时间变得很长,此时就可以采用write buffer来解决这个问题。脏状态的cache-line会首先放到写级存中,等到下级存储器有空闲的时候,才会将写缓存中的数据写到下级存储器中。
这和多一级的cache有什么不同呢?这是一个专门为写操作设计的buffer(注意:load也可能造成写操作)。原因在于我们知道写通常比读更慢,特别对于write-through来说;其次,当上层cache满后,需要先将dirty cache line写回下层cache,再读取下层cache中的数据。若下层cache只有一个读写端口,那么这种串行的过程导致D-Cache发生缺失的处理时间变得很长,此时就可以采用write buffer来解决这个问题。脏状态的cache-line会首先放到写级存中,等到下级存储器有空闲的时候,才会将写缓存中的数据写到下级存储器中。
对于write buffer,我们还可以对其进行 合并(merging) 操作。所谓merging,指的是将在同一个cache-line上的数据一并写入下层cache中,而非多次写入同一个cache-line。
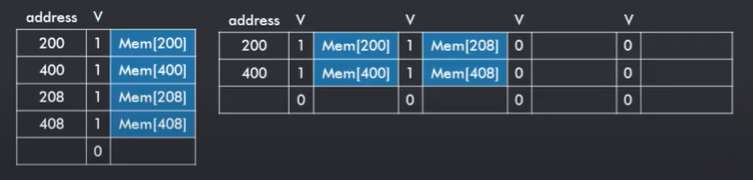
上图中的右侧表示了一个采用了merging write buffer策略的写缓冲区。
critial word first and early restart
先来看一下cache miss时的cpu:
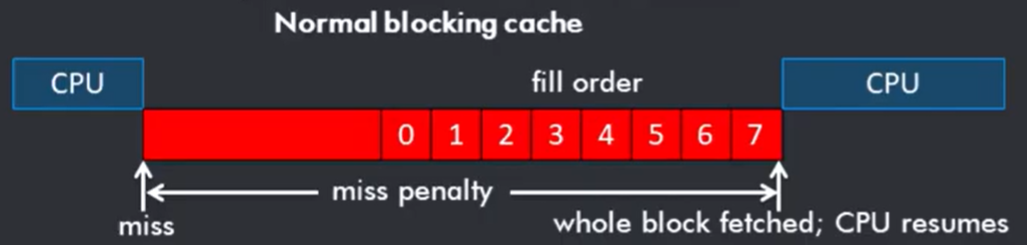 图中展示了一个blocking cache在cache miss时,cpu stall,而后cache将需要取得的cache-line放入后,cpu resume的timeline。我们可以发现,若我们只需要cache-line中的第3个word,cpu完全可以提早resume。如下图所示:
图中展示了一个blocking cache在cache miss时,cpu stall,而后cache将需要取得的cache-line放入后,cpu resume的timeline。我们可以发现,若我们只需要cache-line中的第3个word,cpu完全可以提早resume。如下图所示:
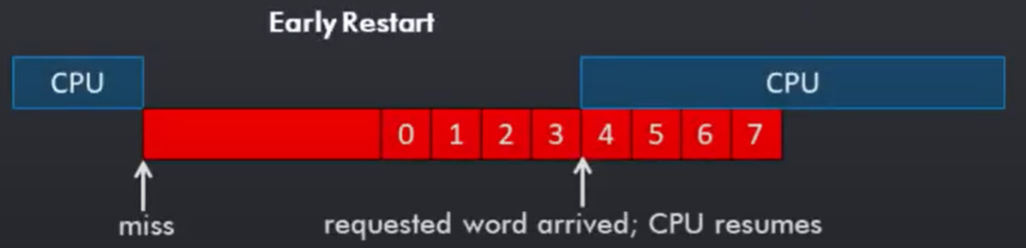
这就是early restart,而critial word first指的是,是在此基础上,在取cache-block时,不按照0~7 word的顺序而是按照3,4,5,6,7,0,1,2的顺序获取,配合early restart以减小miss penalty。
当然,这种优化手段一般在cache-block size越大的时候效果越好。
non-blocking caches
本节主要参考了超标量处理器设计9.6.2
blocking cache:在D-Cache发生缺失并且被解决之前将D-Cache与物理内存之间的数据通路被锁定,只处理当前这个缺失的数据,处理器不能够再执行其他的load/store指令。

这是最容易实现的一种方式,但是考虑到D-Cache缺失的处理时间相对是比较长的,这段时间容易阻塞其他load/store指令的执行,特别是在超标量处理器中,一个周期可能发射多个load/store指令,这样的阻塞就大大减少了程序执行时可以寻找的并行性。
为了解决这个问题,Kroft提出了non-blocking cache,(aka lookup-free cache, aka out-of-order-memory system),如下图所示:
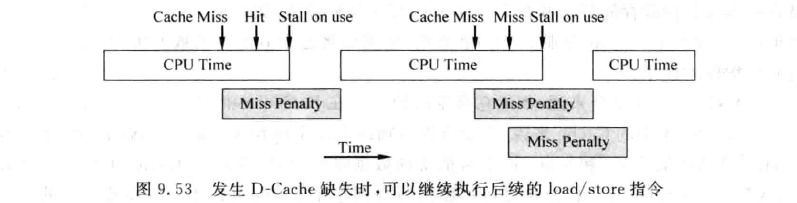
其实就是在cache miss之后,cpu继续发送load/store指令;那么我们可能会有hit after miss,也可能有miss after miss,甚至多次miss连续发生。
我们来看看我们需要增加哪些结构以支持non-blocking cache。
采用这种方法之后,load/store指令的D-Cache缺失被处理完的时间可能和原始的指令顺序不一样了。举例来说,两条顺序的指令load1和load2都发生了D-Cache缺失,但是load1指令可能需要到物理内存中才能够找到需要的数据,而load2指令在L2 Cache中就可以找到所需的数据,因此load2指令会更早地得到需要的数据。要处理这个问题,就需要保存那些已经发生缺失的load/store指令的信息,这样当这些缺失的load/store指令被处理完成,将得到的数据写回到D-Cache时,仍然可以知道哪条load/store 指令需要这个数据。
这个保存原始load/store的结构一般称为MSHR(Miss Status/information Holding Register),如下图所示:
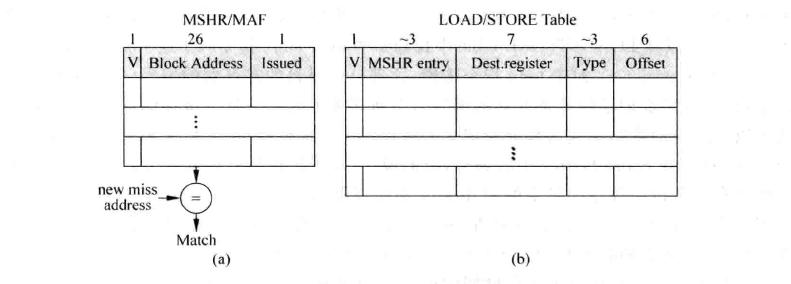
上图中(a)称为MSHR的本体,它只用来保存所有产生首次缺失的load/store 指令的信息,它包括三项内容。
- 首次缺失(Primary Miss): 对于一个给定的地址来说,访问D-Cache时第一次产生的缺失称为首次缺失。
- 再次缺失(Secondary Miss): 在发生了首次缺失并且没有被解决完毕之前,后续的访问存储器的指令再次访问这个发生缺失的Cache line,这时就称为再次缺失。
- V: valid bit用来指示当前的entry是否被占用,当首次缺失发生时,MSHR本体中的一个表项会被占用,此时valid位会被标记为1。当所需要的Cache line从下级存储器中被取回来时,会释放MSHR本体中被占用的表项,因此valid位会被清零。
- Block Address: 指的是Cache line 中数据块(data block)的公共地址。每次当load/store 指令发生D-Cache缺失时,都会在MSHR的本体中在找它所需的数据块是否处于正在被取回的过程中,这需要和Block Address这一项进行比较才可以知道,通过这种方式,所有访向同一个数据块的指令只需要处理一次就可以了,这样可以避免存储器带宽的浪费。
- Issued: 表示发生首次缺失的load/store指令是否已经开始处理。由于存储器的带宽有限,占用MSHR本体的首次缺失不一定马上就会被处理。
上图(b)称为LOAD/STORE Table,保存不论是发生首次缺失还是再次缺失的load/store指令,它包括五项内容。
- V: valid位,表示一个entry是否被占用。
- MSHR entry: 表示一条发生缺失的load/store指令属于MSHR本体中的哪个表项,由于产生D-Cache缺失的许多load/store指令都可能对应着同一个Cache line,为了避免重复地占用下级存储器的带宽,这些指令只会占据MSHR本体中的一个表项,但是它们需要占用LOAD/STORE Table中不同的表项,这样才能够保证每条指令的信息都不会丢失。同时也会记录下这些指令在MSHR本体中占据了哪个表项,这样当一个Cache line被从下级存储器取回来时,通过和MSHR本体中的block address进行比较,就可以知道它在MSHR本体中的位置。然后就可以在LOAD/STORE table中找到哪些load/store指令属于这个Cache line。
- Dest.register: 对于load指令来说,这部分记录目的寄存器的编号(如果采用了寄存器重命名,就需要记录物理寄存器的编号),就可以将对应的数据送到这部分所记录的寄存器中;而对于store指令来说,这部分用来记录store指令在Store Buffer中的编号。(这与超标量的处理有关,暂时不展开)
- Type: 记录访问存储器指令的类型,这部分取决于具体指令集的实现,对于MIPS来说,访向存储器的指令类型包括LW(Load Word)、LH(Load Half word)、LB(Load Byte) 、SW(Store Word)、SH(Store Half word)和SB(Store Byte),通过记录指令的类型,才能够使D-Cache缺失被解决之后,能够继续正确地执行指令。
- Offset: 访向存储器的指令所需要的数据在数据块中的位置,例如对于大小是64字节的数据块来说,这部分的位宽需要6位。
通过MSHR本体和LOAD/STORE Table的配合,可以支持非阻塞的操作方式,当一条访向存储器的指令发生D-Cache缺失时,首先会在找MSHR的本体,这个查找过程是将发生D-Cache缺失的地址和MSHR中所有的block adress进行比较,根据比较的结果,处理如下:
- 如果发现有相等的表项存在,则表示这个缺失的数据块正在被处理,这是再次缺失,此时只需要将这条访问存储器的指令写到LOAD/STORE Table中就可以了。
- 如果没有发现相等的项,则表示缺失的数据块是第一次被处理,也就是首次缺失。此时需要将这条访向存储器的指令写到MSHR本体和LOAD/STORETable两个地方。
如果MSHR本体或者LOAD/STORE Table 中的任意一个已经满了,则表示不能够再处理新的访问存储器指令,此时应该暂停流水线继续选择新的load/store指令送到FU中执行,等待之前的某个D-Cache缺失被解决完毕此时MSHR或者LOAD/STORE Table中就会有空闲的空间了,允许流水线继续执行。在现实世界中的处理器一般出于硅片面积和功耗的考虑,MSHR本体的容量不会很大,多为4~8个,也就是 处理器支持4~8个D-Cache缺失同时进行处理 。
multibank caches
一般cache上的读写端口都只有一个,这样限制了我们的并行性。那么我们增加cache上的读写端口如何呢?以双端口Cache为例,在这种设计中,所有在cache中的控制通路和数据通路都需要进行复制:两套地址解码器,两个多路选择器,比较器的数量多出一倍,两个Aligner(完成字节或半字读取),更重要的是Tag SRAM和Data SRAM的每个cell都需要同时支持两个并行的读取操作。这种方法增大了芯片面积,且功耗随之上升,一般不会在实际的处理器上使用。
那么我们如何既要一次性读取多个数据又要稍微小的硬件代价呢?multibank cache可以实现这样的功能:
我们把cache分成多个不重合的bank,每个bank还是采用单端口的设计。若在一个周期中,我们所要操作的数据“均匀的”分布在不同的bank当中,我们就可以一次性对多块数据进行操作。这时候,我们只需要增加一些控制通路,但是不用让每个cell都支持并行读取,有效地减小了硬件复杂度。
影响这种multibank cache性能的关键因素是bank-conflict:它指的是 若我们某一周期内对cache的操作数据集中在一个bank上,我们就必须串行的完成访问,相当于丧失了bank的作用。 如何降低bank-conflict呢?一种启发式的切分bank的方法是interleaving得把连续的cache-line分到不同的bank中,如下图:
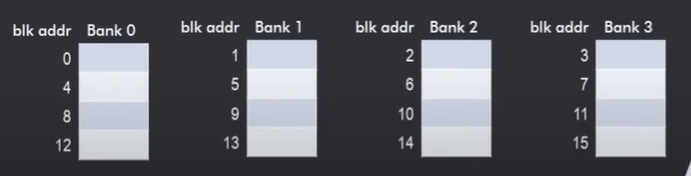
主要的思想就是我们经常同时对相连得cache-line进行访问,那么把它们放在不同的bank里就能避免bank conflict。
值得一提的是,multibank也是一种提高main memory bandwidth的技巧。
summary
还有一些软件硬件技巧,如prefetch,分块,way-predicting caches等就不一一展开了。
working with TLB: VIPT(Virtual Indexed physical Tagged)
在学习TLB相关知识后,我们常认为cpu关于地址翻译的过程是如下图所示的(忽略ASID):将virtual address经由TLB/page table翻译为物理地址,在利用该物理地址在cache hierarchy中获取数据。
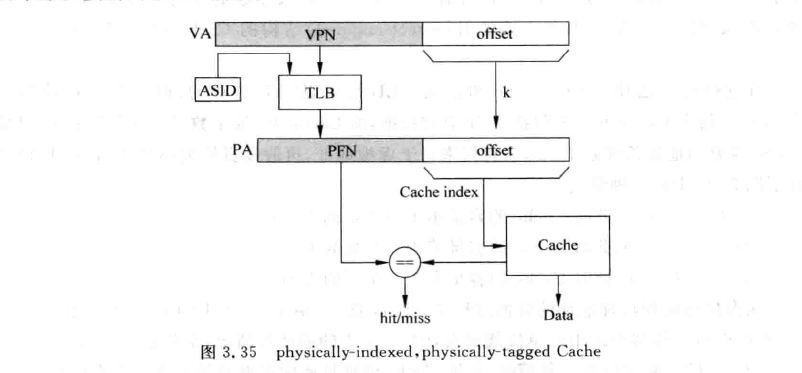
这种设计在理论上是完全没有问题的,但在真实的处理器中却很少被采用。因为他完全串行了TLB和Cache的访问。事实上我们在上图中可以看出,VA到PA的转化时,低位的offset是完全没有变化的。若物理地址中寻址Cache的部分使用offset就足够的话,那么就不需要等到TLB得到物理地址后再去寻址Cache,而是直接使用虚拟地址的offet部分。 如下图所示:
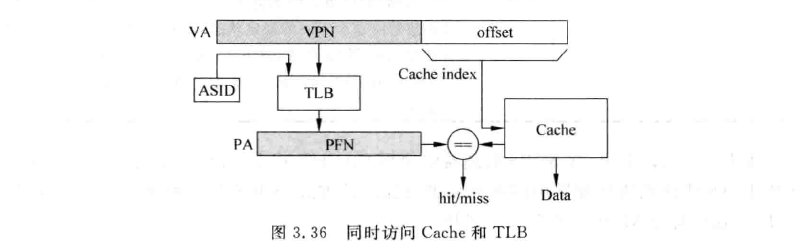 相当于用VA做Index,用PA做Tag。这就是VIPT(virtual indexed physical tagged),当然,这只是VIPT的一种情况。
相当于用VA做Index,用PA做Tag。这就是VIPT(virtual indexed physical tagged),当然,这只是VIPT的一种情况。
假设每个Cache line中包含$2^b$个字节数据,Cache Line的数量是$2^L$,$k$为页大小。那么我们会有几种情况:
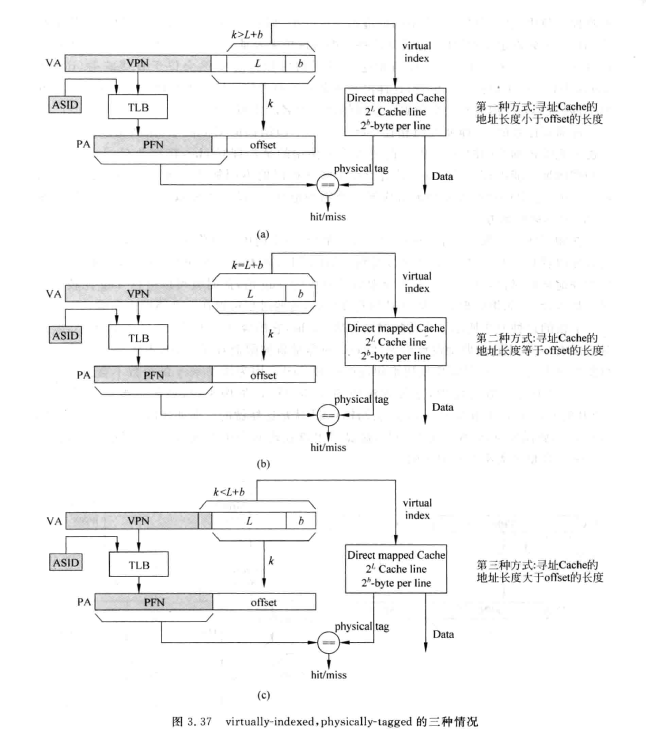 先看前两种情况,实现比较简单,他们的virtual index部分实际上与physical index是一样的(应为在block-offset内,不参与地址翻译)。
先看前两种情况,实现比较简单,他们的virtual index部分实际上与physical index是一样的(应为在block-offset内,不参与地址翻译)。
但前两种情况也有缺点,就是这种结构限制了cache的大小,cache的byte数不能超过$2^k(一般为4KB)$。我们现在随便一个l1i-cache就有64~128KiB。要想使用更大的Cache,在不考虑图中(c)结构时,可以采用增加way的个数,这不会引起寻址Cache需要位数的增加。但我们粗略的估算一下,若cache为128KiB,页大小为4KiB,那么我们需要32way的L1i-Cache。根据经验我们不会使用way数这么大的cache,因为这会使得比对tag的时延大大上升。
那么,如何才能摆脱cache容量受限制这一问题呢?解决方案就是让$L+b>k$,也就是图中(c)的设计,这种设计就是真正的virtual-indexed。但这会遇到 重名(aliasing) 问题:不同的虚拟地址会对应同一个物理地址。例如在页大小为4KB的系统中,有两个不同虚报地址 VA1和VA2,映射到同一个物理地址PA。有一个直接映射结构的Cache,容量为8KB,需要13位的index才可以对其进行寻址,如下图:
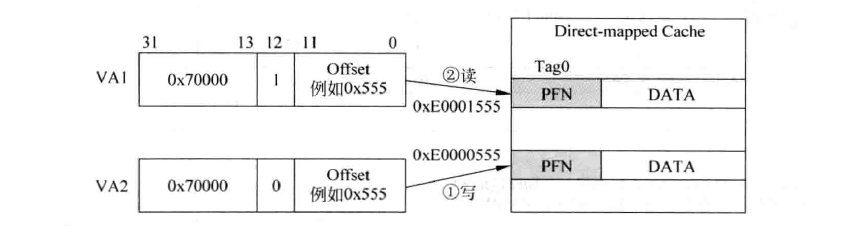 此时va1与va2的cache index不同,也就造成了Cache中的不同位置存放着物理存储器中的同一位置中的数据。这造成了Cache的浪费,且还会有一致性上的问题。
如何解决呢?可以用bank的方式或者利用下层cache做标记的方式。这里就不仔细展开了
此时va1与va2的cache index不同,也就造成了Cache中的不同位置存放着物理存储器中的同一位置中的数据。这造成了Cache的浪费,且还会有一致性上的问题。
如何解决呢?可以用bank的方式或者利用下层cache做标记的方式。这里就不仔细展开了
reference
- youtube上一个讲memory hierachy design的系列
- 超标量处理器设计 姚永斌
- H&P Computer Architecture: A Quantitative Approach
- coursera上Princeton的Computer Architecture 高级体系结构课程,介绍了超标量乱序多发射结构cpu等