H&P那本关于分支预测的部分比较简短且表述有点晦涩,(顺便吐槽一下第五版的中文翻译,建议看英文原版)本文主要参考超标量处理器设计,国人写的,用语符合习惯,强烈推荐!
Motivation
在处理器中,除了cache之外,另一个重要的内容就是分支预测,它和cache一起左右处理器的性能。以SPECint95作为benchmark,完美的cache和BP(branch-predictor)能使IPC提高两倍左右:
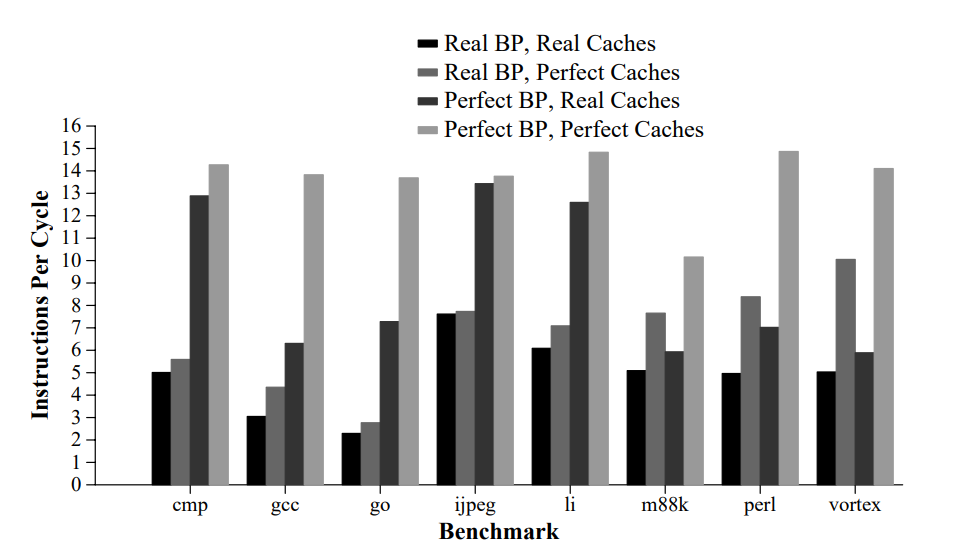
图片来自论文SSMT。当然,这是21世纪之前的结果了。现代处理器分支预测普遍能达到97%~98%以上的精度,在多数浮点benchmark中基本都是99%的准确率。
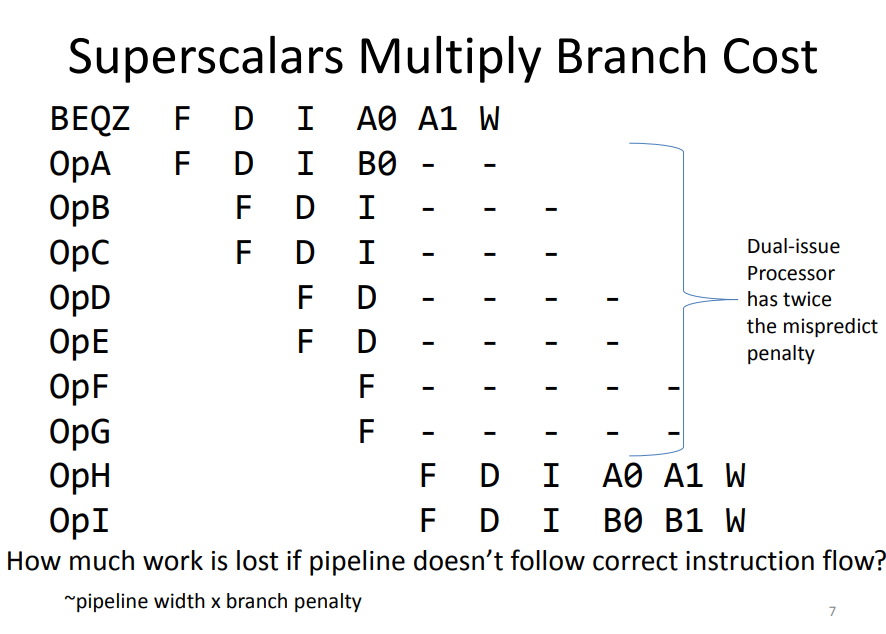
为什么需要这么高的精度呢? 一般情况下,分支指令的占比通常在 15% 到 30% 之间。对于经典五级流水线无分支预测cpu,一个branch会造成一次stall;而对于现代的superscalar且流水线级数远高于5的(一般是二十级以上)cpu,其misprediction penalty是 $M * N$ 的(M = fetch group内指令数, N = branch resolution latency,就是决定分支最终是否跳转需要多少周期)。如下图所示:
 我们再做一个定量实验:
假设我们有一个
我们再做一个定量实验:
假设我们有一个
- $ N = 20 (20\ pipe stages), W = 5 (5\ wide fetch) $
- 1 out of 5 instructions is a branch
- Each 5 instruction-block ends with a branch
的CPU,那么我们取出500条指令需要多少个周期呢?
- 100% 预测正确率
- 100 个时钟周期 (all instructions fetched on the correct path)
- 无额外工作
- 99% 预测正确率
- 100 (correct path) + 20 (wrong path) = 120 个时钟周期
- 20% 额外指令被取出
- 98% 预测正确率
- 100 (correct path) + 20 * 2 (wrong path) = 140 个时钟周期
- 40% 额外指令被取出
- 95% 预测正确率
- 100 (correct path) + 20 * 5 (wrong path) = 200 个时钟周期
- 100% 额外指令被取出
可以看出,分支预测失败在现代的超标量多流水线cpu中的penalty被极大的放大了。所以分支预测的正确性就显得额外重要。
Taken/Not Taken
静态分支预测
branch delay slots
这是一种软硬件结合的静态分支预测方法,准确的说这不算是一种预测的方法。它要求编译器找出和分支是否发生无关的指令(例如,分支前的指令且没有data dependance)重排到分支指令之后,这样无论分支是否发生,后面的指令都需要执行,以此解决stall的问题。早期的MIPS cpu会采用这种设计。不幸的是,随着cpu的流水线层数越来越多,编译器必须找到N条与该分支指令无关的指令(N为决定分支最终是否跳转需要多少周期)才能喂满delay slots达到没有stall的效果。且随着superscalar架构的流行,这种设计在硬件上也有许多难以解决的冲突,因此最终离开了历史舞台。
always Taken or always Not Taken
预测分支总是发生/不发生是最简单的分支预测方法。此外,我们还有这样的规律可以利用:
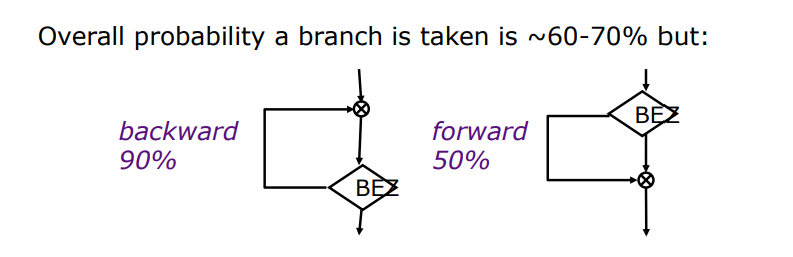 这是因为在循环中,分支backward跳转发生的几率是很大的。那我们或许可以在此事实上建立一个Backward Branch Taken, Forward Branch Not Taken的预测方法。
这是因为在循环中,分支backward跳转发生的几率是很大的。那我们或许可以在此事实上建立一个Backward Branch Taken, Forward Branch Not Taken的预测方法。
- Always Predict Not-Taken
- Basically o nothing, simple to implement
- Know fall-through PC in Fetch
- Poor Accuracy, especially on backward branches
- Always Predict Taken
- Difficult to implement because don’t know target until Decode
- Poor accuracy on if-then-else
- Backward Branch Taken, Forward Branch Not Taken
- Better Accuracy
- Difficult to implement because don’t know target until Decode
这些方法都能显著提高分支预测的成功率,但是远远还达不到95%以上的准确率。
动态分支预测
动态分支预测中的动态,按我的理解,指的是根据历史分支跳转情况调整接下来的分支预测方向。
2-bit predictor
一个最intuitive的方式就是我们用上一次分支是否跳转来预测当前分支是否跳转。注意,这里的上一次指的是 上次执行该分支指令时是否跳转,而并不是依据上一条分支来预测本分支。 实现方式也比较简单:我们将所有分支指令(的地址)都对应一个bit,来表示上次跳转的结果。具体细节可以看后面2-bit predictor
这种预测方式至少在循环中能有不错的结果——若循环m次,则missprediction为$\frac{1}{m} \ or\ \frac{2}{m}$(如果第一次默认为不跳转那么第一次循环会被预测错误)。但是在某种极端情况下,它的分支正确率为0%
for (int i = 0; i < n; i ++) {
if (a[i] % 2 == 0) { // <--- branch A
do something;
} else {
do something else;
}
}
对于branch A 这个分支,若a数组中的元素为奇偶交替出现,且$a[0]$为奇数,则实际跳转为$TNTNTNTNTN… (T:taken, N: not taken)$;不幸的是,我们将用于该分支的预测的bit初始化为0,那么我们会预测为$NTNTNTNT…$ 其失败率将为100%!
为了避免这种问题,人们发明了2-bit predictor——每个分支的历史信息用两个bit来维护。其状态图如下:
 其实
其实2-bit predictor很类似于LRU-k的思想,对于抖动的程序有更好的效果:比如对于$TTTNTTT$的分支,2-bit predictor会容忍其中的Not Taken,只是将状态由Strongly Taken转变为Weakly Taken,但在$N$发生的下一次仍然会预测为$T$。所以它就可以有效地防止在$TNTNTNTNTN…$的情况下失败率为100%。
另外,对于多重循环:
for (int i = 0; i < n; i ++) {
for (int j = 0; j < m; j ++) {
do something;
}
}
2-bit predictor 对内层循环的准确率就是$\frac{1}{m}$的(除了第一次外层循环),这也优于用1-bit predictor的情况。
我们在来考虑如何实现2-bit predictor:
最直接的方法是我们对每条指令(即便他不是分支指令)都要有一个独立的predictor,那么在32位机器中这就要求存储空间 $2^{30} * 2 bit \approx 0.25 GB$,这么大的额外的硅芯面积显然是无法接受的。
我们可以用下图所示来存储2-bit predictor的值:
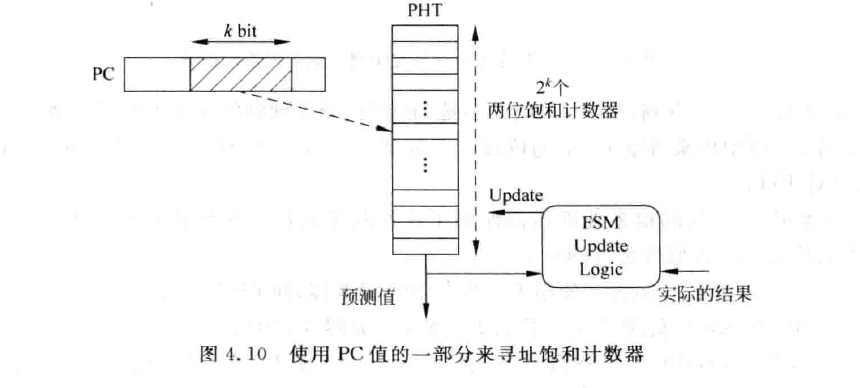 图中的PHT(pattern history table)存放的就是所有PC值对应的2-bit predictor。我们只用了PC值当中的k位来对PHT进行寻址,因此PHT的大小就是$2^{k} \times 2bit$的。但使用这种方式来寻址PHT,必然就会导致那k-bit相同的PC映射到相同的PHT entry上,这种情况称为
图中的PHT(pattern history table)存放的就是所有PC值对应的2-bit predictor。我们只用了PC值当中的k位来对PHT进行寻址,因此PHT的大小就是$2^{k} \times 2bit$的。但使用这种方式来寻址PHT,必然就会导致那k-bit相同的PC映射到相同的PHT entry上,这种情况称为aliasing,aliasing会对分支预测的准确度产生影响。这就是设计者得做出的trade-off了,增大k能提高准确率但需要消耗更多硬件。我们还可以将PC的经过某种哈希后再取k位,这样能减少碰撞概率。
我们按照从用1-bit来记录历史跳转情况到用2-bit记录的思路,是否可以用n-bit来记录,以使得我们的预测跳转部件对程序跳转抖动更加容忍呢?大量的测试表明,再往上加bit的数量已经无益于准确率的提高了。
2-bit predictor是90年代比较主流的分支预测方法,4K-entry BHT, 2 bits/entry 已经基本能达到 80%~90% 左右的正确率了。
Local History Branch Prediction
我们现在考虑一种带有“循环节”的分支跳转模式:$TTNNTTNNTTNN…$,我们的2-bit predictor没法“观察”到这种规律并加以利用。那该如何解决呢?我们可以对 每一条分支使用一个寄存器来记录该分支在过去的历史状态,只要这个历史状态很有规律,我们就能利用它,这样的寄存器称为分支历史寄存器(Branch History Register, BHR)。我们用一个n-bit的BHR记录一条指令过去n次的执行情况,对一个BHR,用多个2-bit predictor捕捉规律。
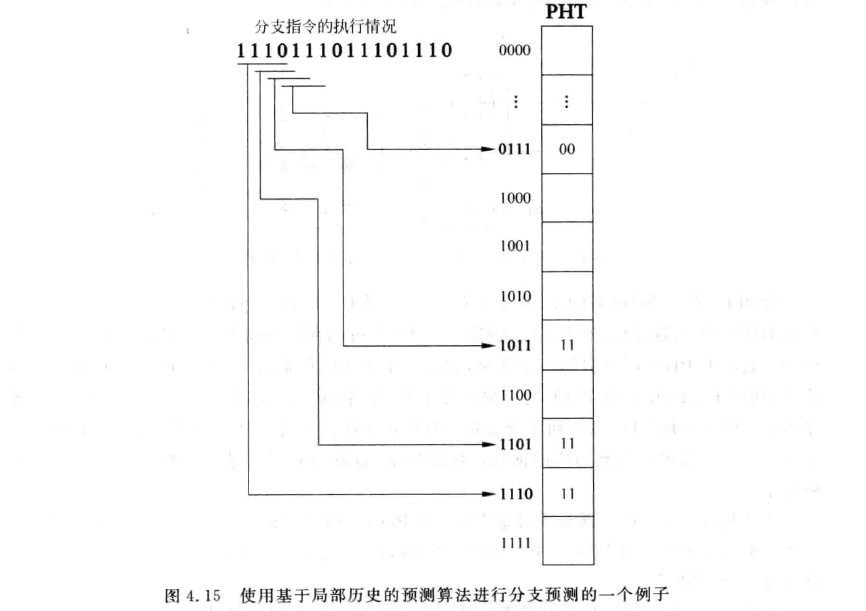 上图中,我们用一个4-bit的BHR分支记录历史,经过足够多次的预热,当我们的BHR从
上图中,我们用一个4-bit的BHR分支记录历史,经过足够多次的预热,当我们的BHR从1011变成0001时,对应的2-bit predictor从11变成了00。这样就捕捉了图中TTTTNTTTTN...的循环规律。
引入BHR增加了硬件的复杂性,对于BHR需要预热/训练的次数,取决于BHR的位数,位数越多需要训练次数越多,但也能预测更大的循环节的分支。为了减少硬件开销,我们也可以只用PC的k个bit来对应一个BHR,如下图所示:
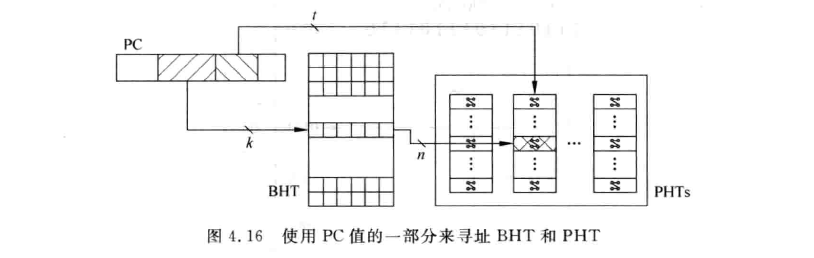 这也会带来不同PC的分支可能被映射到同意BHR的问题,我们可以通过将PC进行哈希、PC与BHR拼接或异或后映射到PHT等方法提升准确度。Again,这也会增加硬件的复杂性。
这也会带来不同PC的分支可能被映射到同意BHR的问题,我们可以通过将PC进行哈希、PC与BHR拼接或异或后映射到PHT等方法提升准确度。Again,这也会增加硬件的复杂性。
Global History Branch Prediction
我们通过BHR的设计已经把对同一条分支指令的动态预测处理到极致了(对于没有循环节规律的分支,我们还有办法预测吗?这是不是很像经典的机器学习问题?事实上,早在2000年,就已经提出了用感知机进行动态分支预测的方法,效果也很不错)。
于是人们又想,分支预测除了本分支历史结果有关,是否还和其他分支有关呢?借助这样的启发式规则,发明了基于全局历史的分支预测方法。对于某一条分支指令,全局指的就是其他分支指令。考虑下面一段代码:
if(a == 2) a = 0;
if(b == 2) b = 0;
if(a != bb) { ... };
分析这一段代码,容易发现当第一条、第二条分支指令不执行时(即操作a = 0、b = 0),第三条指令一定会执行。如何记录全局分支呢?与局部历史分支预测类似的,我们用一个寄存器来记录全局历史分支跳转情况,这个寄存器称为 Global History Register(GHR)。与BHR不同的是,我们不需要对所有PC都记录一个历史分支跳转的值,而只需要一个全局的GHR就可以。一个简单的基于全局历史的分支预测如下:
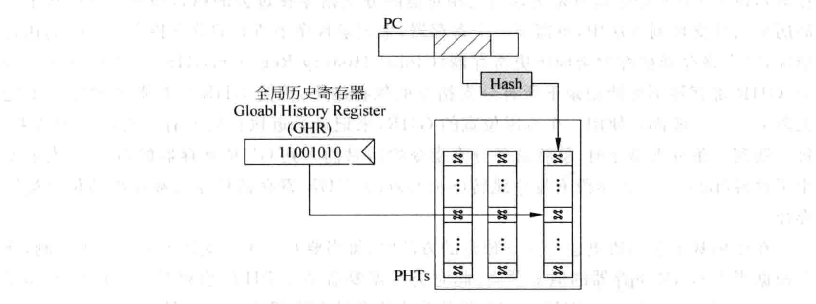
事实上Global branch predictor对比2-bit predictor在small predictor sizes(我的理解是GHR的位数很少)的时候表现更差(见McFarling93) 这主要是因为不同的分支经常有这相同的“全局历史”,特别是当GHR位数较少时,他们容易被映射到相同的2-bit predictor上。
Tournament Predictors: Adaptively Combining Local and Global Predictors
显然,我们可以想办法结合 Global History Branch Prediction和 Local History Branch Prediction。Tournament Predictor就是一个经典的例子:
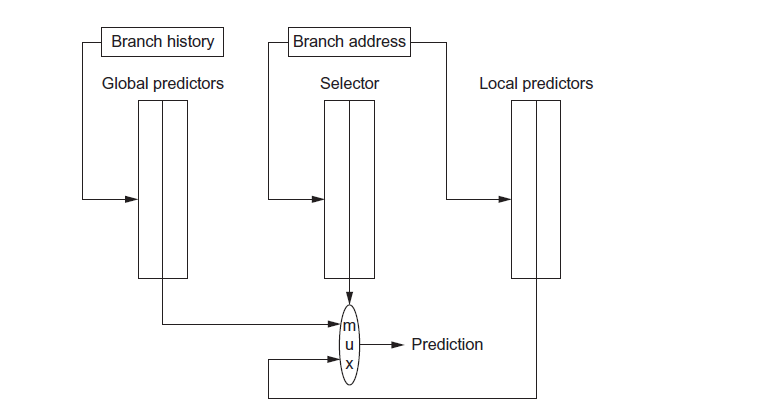
我们用一个selector来选择使用Global predictor的结果还是用Loacal Predictor的结果。具体这个selector应该如何实现呢?其基本思想就是用一个类似于2-bit predictor的东西来训练选哪个predictor:
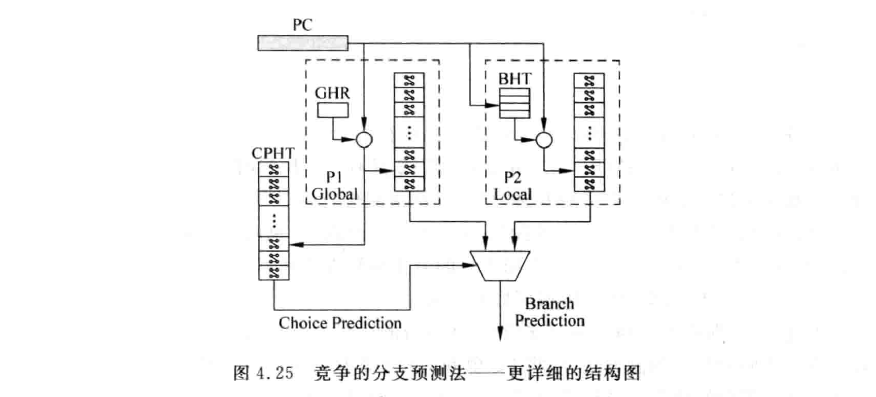 根据以往的分支预测结果训练selector。
根据以往的分支预测结果训练selector。
SOTA: TAGE
很多现代CPU都使用了基于 TAGE(TAgged GEometric History Length Branch Prediction) 的思想的分支预测器。这种方法早在2006年就已提出。此后TAGE及其变种连续蝉联CBP(Championship Branch Prediction)比赛的冠军(是的,竟然还有个专门做分支预测的比赛)。
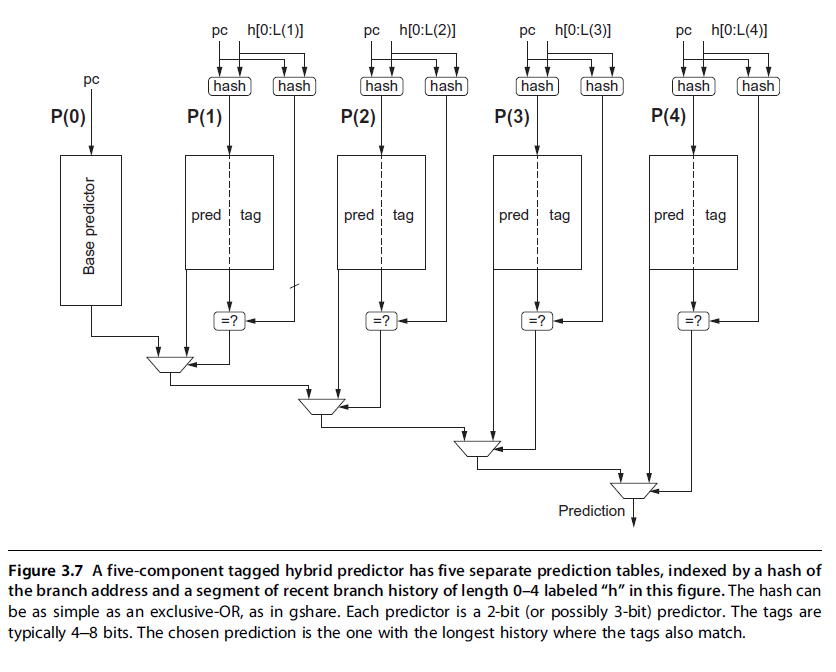 如图所示,其基本思想是:由多个Global predictor组成,每个global predictor由PC和GHR的不同长度的值映射到BHT表中得到。在此基础上增加了tag和预测结果进行比较。给出的结果于具有最长分支历史且具有匹配标记的预测器。P(0)始终匹配,因为它不使用tag,在P(1)到P(n)中没有任何一个匹配时,使用P(0)。具体细节可以看原论文。
如图所示,其基本思想是:由多个Global predictor组成,每个global predictor由PC和GHR的不同长度的值映射到BHT表中得到。在此基础上增加了tag和预测结果进行比较。给出的结果于具有最长分支历史且具有匹配标记的预测器。P(0)始终匹配,因为它不使用tag,在P(1)到P(n)中没有任何一个匹配时,使用P(0)。具体细节可以看原论文。
跳转地址
分支预测除了需要预测该次跳转是否发生,还有一个重要问题就是我们需要预测出target address。
分支的跳转可以分为直接跳转和间接跳转。直接跳转的目标地址以立即数的形式存在指令中,那么我们就能在译码时得到预测的地址,但是由于现代处理器流水线更长,取指就可能被分成多段,所以我们需要在已得到PC时就预测跳转结果地址。对于间接跳转的分支,目标地址存在通用寄存器中,会更加难以预测。下文只简单介绍直接跳转时的 target address 预测,对于间接跳转的地址预测,可以参考《超标量处理器设计》4.3.2
直接跳转
分为两种情况:
- 分支指令不发生跳转: $target\ addr = cur\ PC + sizeof(fetch\ group)$
- 分支指令发生跳转: $target\ addr = cur\ PC + SignExd(offset)$
第一种情况我们可以在上述 Taken/Not Taken 得到结果后,若是NT,则马上得到target addr.
而对于第二种情况,我们取指完才能得到target addr,这是不可以接受的。所以我们要在刚知道PC时就进行结果预测。如何预测呢?其实就是用一个cache来记录。由于一个进程的分支指令的地址是不会改变的,即PC为分支的指令一直都是分支指令,那么我们只要将其记录结果下来,就可以在之后的预测中在取得PC时候就通过cache得到target addr 。这里cache被称作BTB(Branch Target Buffer)。
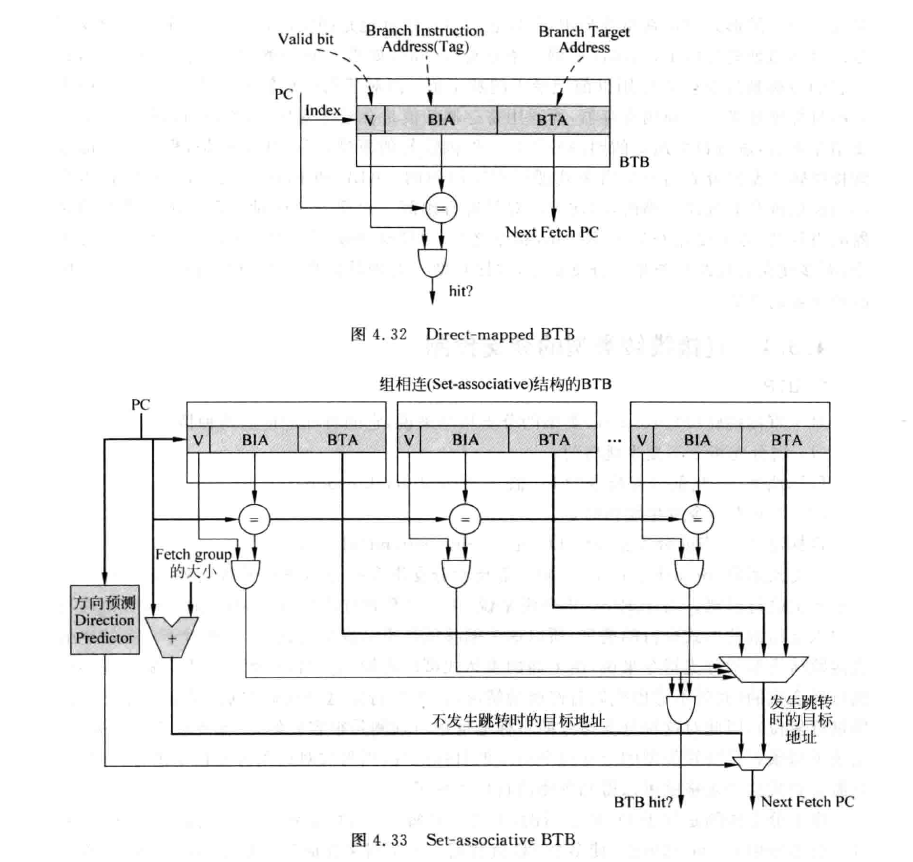 实现也与普通的cache没有多大区别。
实现也与普通的cache没有多大区别。
reference
- 超标量处理器设计 姚永斌
- H&P Computer Architecture: A Quantitative Approach
- coursera上Princeton的Computer Architecture 高级体系结构课程,介绍了超标量乱序多发射结构cpu等