介绍
什么是内存模型(Memory Model)呢?这里介绍的内存模型并非C++对象的内存排布模型,而是一个非编程语言层面的概念。我们知道在C++11中,标准引入了 std::atomic<>原子对象,同时还引入了
memory_order_relaxed
memory_order_consume
memory_order_acquire
memory_order_release
memory_order_acq_rel
memory_order_seq_cst
这六种 memory order。引入可以让我们进行无锁编程,而如果你想要更高性能的程序,你就必须深挖这六种内存模型的含义并正确应用。(当然,在不显式指明memory order的情况下,你能保证获得正确的代码,但存在性能损失)
内存模型
在介绍C++ memory order之前,我们先回答另一个问题。你的计算机执行的程序就是你写的程序吗? —— 显然不是的。
原因也很简单,为了更高效的执行指令,编译器、CPU结构、缓存及其他硬件系统都会对指令进行增删,修改,重排。但要回答具体进行了什么样的修改,又是一个极其复杂的问题。或者说,整个现代体系结构,就是在保证程序正确性的前提下利用各种手段对程序优化。我们可以粗略的将其分成几个部分:
- source code order: 程序员在源代码中指定的顺序
- program code order: 基本上可以看成汇编/机器码的顺序,它可以由编译器优化后得到
- execution code order: CPU执行指令顺序也不见得与汇编相同,不同CPU在执行相同机器码时任然存在优化空间。
- perceived order/physical order: 最终的执行顺序。即便CPU按照某种确定指令执行,物理时间上的执行顺序仍然可能不同。例如,在超标量CPU中,一次可以fetch and decode多个指令,这些指令之间的物理执行顺序就是不确定的;由于不同层级缓存之间延时不同,以及缓存之间的通信需要等带来的不确定的执行顺序等

上图简要说明了你的源代码可能经历的优化步骤。
这些优化的一个主要原因在于 掩盖memory access操作与CPU执行速度上的巨大鸿沟。如果没有cache,CPU每个访存指令都需要stall一两百个时钟周期,这是不可接受的。但是引入cache的同时又会带来 cache coherence等问题,这也是造成x初始为0,两个线程同时执行 x++,而x最终不一定为 2的元凶。而一个内存模型则对上述并发程序的同一块内存进行了一定的限制,它给出了在并发程序下,任意一组写操作时,可能读到的值。 不同体系结构(x86, arm, power…)通过不同的内存模型来保证程序的正确性。
bonus question: 不同等级的cache latency?
answer: l1: 1ns, l2: 5ns, l3: 50~100ns, main memory: 200ns
Sequential Consistency(SC)
SC是最严格的内存模型,也被称作non-weak memory model。在该模型下,多线程程序执行的可做如下分析:对于每一步,随机选择一个线程,并执行该线程执行中的下一步(例如,按程序或编译的顺序)。重复这个过程,直到整个程序终止。这实际上等效于按照(程序或编译的)顺序执行所有线程的所有步骤,并以某种方式交错它们,从而产生所有步骤的单一总顺序。SC不允许重新排列线程的步骤。因此,每当访问对象时,都会检索该顺序中存储在对象中的最后一个值。(注意,内存模型中说的重新排列与编译器层面无关,编译器自然是可以讲没有data dependance的读写操作进行重排的,只要保证程序的正确性即可。内存模型中的重排指的是在硬件执行阶段,由于cache hierarchy等引发的一些问题导致指令物理执行顺序被改变)。
也就是说,我们可以抽象出一个简单的内存结构:
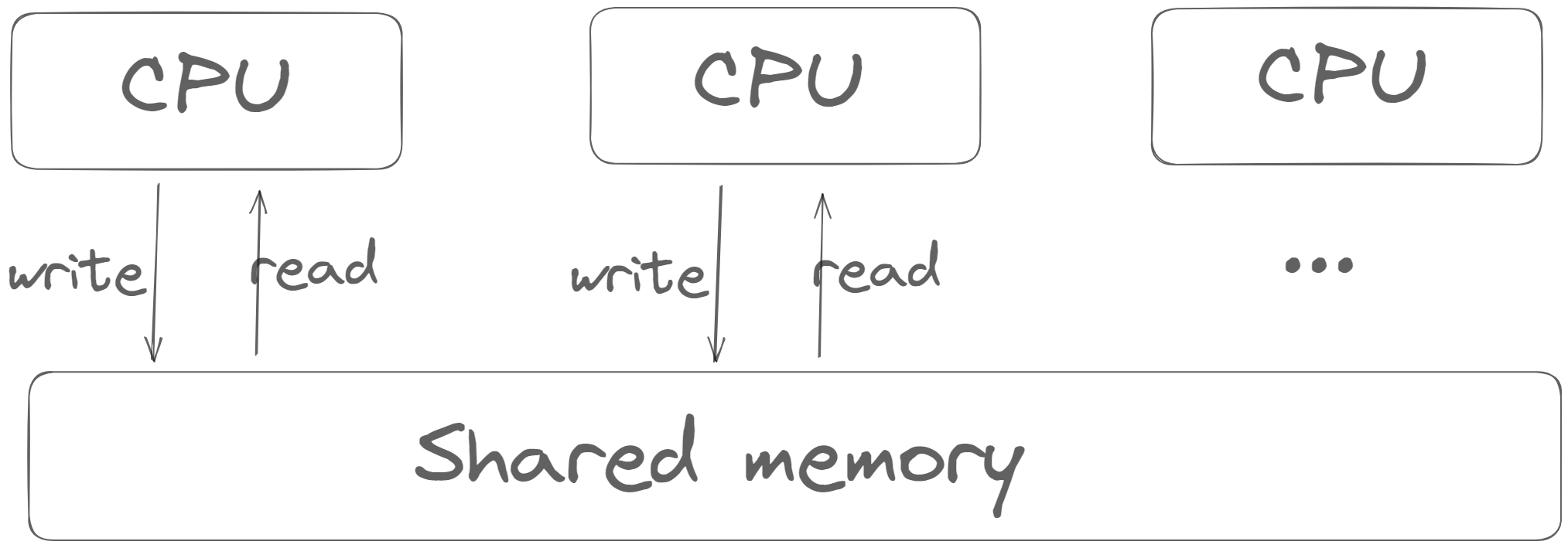 在这种结构中,我们隐藏了cache与store buffer的存在,或者说SC协议允许我们无视这两个硬件。
那么,我们对于下面表格中的问题就有确定的答案:
在这种结构中,我们隐藏了cache与store buffer的存在,或者说SC协议允许我们无视这两个硬件。
那么,我们对于下面表格中的问题就有确定的答案:
| Thread 1 | Thread 2 | main |
|---|---|---|
| x = 1 | y = 1 | x = 0, y = 0 |
| y’ = y | x’ = x | Spawn thread 1, 2; Wait for threads |
显然,在SC模型中最终的结果只可能是:
- x = 1, y = 1;
- x = 0, y = 1;
- x = 1, y = 0;
而不会出现 x = 0; y = 0的情况。
SC模型很美好,分析起来简单,心智负担小。但是为了保证顺序一致性,他付出了一定的性能代价。所以,并没有哪个成熟的体系结构真正使用SC模型。现代体系结构纷纷为了性能而做出了不同程度的妥协。
x86-TSO
x86-TSO(Total Store Order),它比SC更弱,但仍是现代CPU约束最强的内存模型其中之一。tso的架构可以用以下抽象来代替:
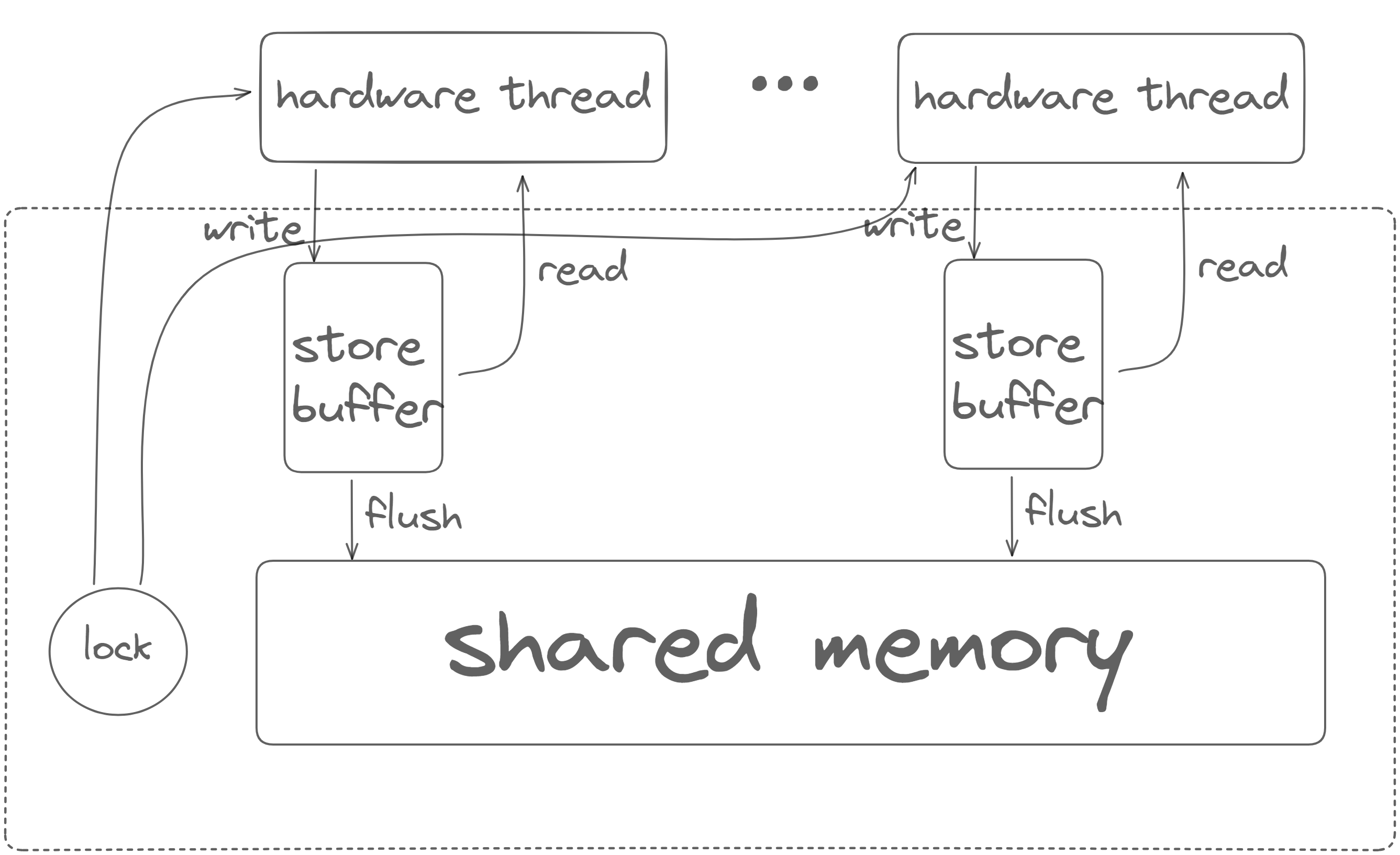 注意,这并非真实的x86的架构(毕竟连cache都没有),只是x86-tso模型保证我们得到这样的抽象。这里的store buffer(或者叫write buffer)也不一定对应着硬件上的store buffer。它也可以是cache hierarchy的一部分,他们之间有一致性协议进行约束来保证上图中的效果。
注意,这并非真实的x86的架构(毕竟连cache都没有),只是x86-tso模型保证我们得到这样的抽象。这里的store buffer(或者叫write buffer)也不一定对应着硬件上的store buffer。它也可以是cache hierarchy的一部分,他们之间有一致性协议进行约束来保证上图中的效果。
TSO模型最重要的几个特性:
- store buffer是FIFO的,读取线程必须读取其自身最近缓冲的写操作,如果有的话,读取的地址与该写操作一致。否则,读取操作将从共享内存中满足。
- mfence 指令会清空该hardware thread的store buffer
- 要执行一个带锁的指令,线程必须首先获取全局锁。在指令结束时,它会清空自己的store buffer并释放锁。当一个线程持有锁时,其他线程无法读取。这基本上意味着带锁的指令强制实现了顺序一致性。
- 线程的可以在任何时间传播到共享内存中,除非另一个线程持有锁。
在TSO下,对于上述表格中的问题,则可能出现 x = 0, y = 0的结果:x = 1与 y = 1都被放到store buffer上而未被flush到shared memory中。
也就是说: x86-TSO does not permit local reordering except of reads after writes to different addresses.
thread 1, thread 2 可能会 thread 1, thread 2
write a, write b ----> read b, read a
read b, read a write a, write b
要解决这个问题也很简单,在write后加上mfence指令即可,它会将store buffer中的存储刷到shared memory中。 这也是TSO比SC理论性能更高的原因,它舍弃了一定的正确性,来减少每次写操作都flush store buffer的开销。
Fun Fact: intel和amd从没承认过他们的x86一定符合x86-tso内存模型,但是他们进行过黑盒测试,结果证明了这一点。(就连设计者都难以reason出理论上的结果,而是通过测试证明的)
ARM and POWER
Arm and power则有着更加宽松的内存模型。为了理解这样一台机器的行为,我们可以认为每个hardware thread都拥有自己的内存副本,如下图所示。所有内存副本和它们的interconnection(即除了线程以外的一切)的集合通常被称为storage subsystem。一个线程的写操作可能以任何顺序传播到其他线程,并且不同地址的写操作的传播可以任意交错,除非它们受到屏障或缓存一致性的限制。也可以将屏障视为从执行它们的硬件线程传播到每个其他线程的操作。
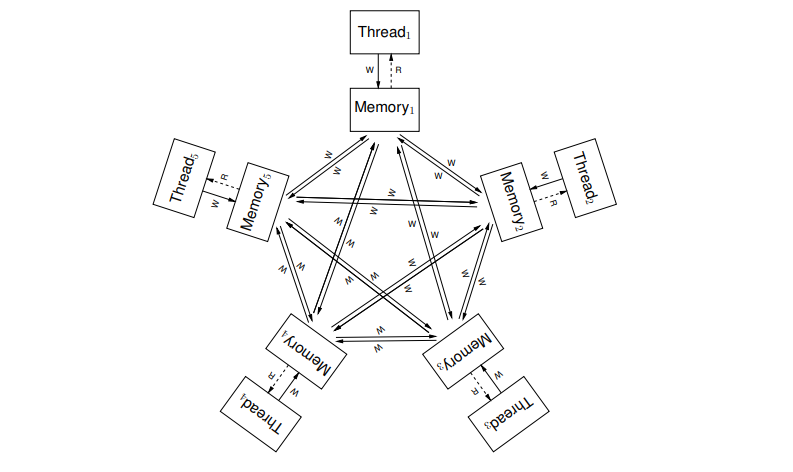
由于每个线程都有自己的子存储系统,它们之间的同步就需要fence进行保障。ARM和POWER提供了barrier(fence)指令(分别是 dbm 和 sync)来约束下面几种顺序:
- Read/Read之间fence:保证他们按照program order执行
- Read/Write屏障: 确保在写操作被提交(因此传播并对其他人可见)之前,读操作被满足并提交。
- Write/Write屏障:确保第一个写操作在第二个写操作被提交之前被提交并传播到所有其他线程。
- Write/Read屏障:确保在读操作被满足之前,写操作已被提交并传播到所有其他线程。
POWER架构还提供了一个额外的“轻量级同步”指令,称为
lwsync,它比sync指令更弱,也因此可能更快。具体作用不在此处赘述。
除了屏障之外,这些体系结构还提供以下依赖关系来强制顺序:
- Address dependency:当第一条指令读取的值用于计算第二条指令的地址时,从一个读操作到程序顺序后的读或写之间存在地址依赖。
- Control dependency:当第一条指令读取的值用于计算在第二条指令之前的程序顺序条件分支的条件时,从一个读操作到程序顺序后的读/写之间存在控制依赖。
- Data dependency:当第一条指令读取的值用于计算由第二条指令写入的值时,从一个读操作到程序顺序后的写之间存在数据依赖。
在ARM和POWER处理器中,read-to-read的control dependency力度较小,因为它们可以在条件分支之前进行推测性执行,从而在第一次读取之前满足第二次读取。为了增加read-to-Read的控制依赖的影响力,可以在条件分支和第二次读取之间添加一个ISB(ARM)或isync(POWER)指令。 相反,read-to-write的control dependency具有一定的影响力:在分支被提交之前,写操作不会被其他任何线程看到,因此也不会在第一次读取的值固定之前被看到。 总结一下,从一个读取到另一个读取,如果存在address dependency 或带有 ISB/isync 的控制依赖,将阻止第二个读取在第一个读取之前被满足,而纯粹的control dependency则不会。从读取到写入,地址、控制或数据依赖都将阻止写入在读取的值固定之前对任何其他线程可见。
C++ memory order
对于 weak memory model,特别是上面介绍的ARM的内存模型,想要精细的控制程序的允许重排的程度需要非常大的心智负担。(光是不同体系结构,不同等级的fence指令就令人望而却步)。因此C++11标准提供的六种memory order就是从语言层面来约束最终希望达到的对程序被优化程度的限制。现在我们再看这几种memory order就比较清晰了。(以下说法并不严谨,但是作为程序员的take away完全足够了。
| Memory Order | Explaination |
|---|---|
| memory_order_relaxed | 表示这个R/W操作除了原子性外没有任何其他限制,他可能会被重排到程序的任何位置(当然,编译器不会允许将他重排到同一个线程对同一个原子变量写操作的前面,这违背了正确性) |
| memory_order_consume | (只用于读) 后面依赖此原子变量的访存指令不允许重排至此条指令之前。 注意,当前标准中的memory_order_consume是没有实际用处的, 一般情况下不要使用 |
| memory_order_acuqire | (只用于读) 后面访存指令不允许重排至此条指令之前 |
| memory_order_release | (只用于写) 前面访存指令不允许重排至此条指令之后。当此条指令的结果对其他线程可见后,之前的所有指令都可见 |
| memory_order_acq_rel | acquire + release语意 |
| memory_order_seq_cst | 满足sequential_consistency内存模型 |
在默认情况下,std::atomic<>相关函数总是选用 std::memory_order_seq_cst,它能有效地帮我们避免错误。但是,我们既然都使用 atomic而不是 mutex了,自然是对性能有较高要求。
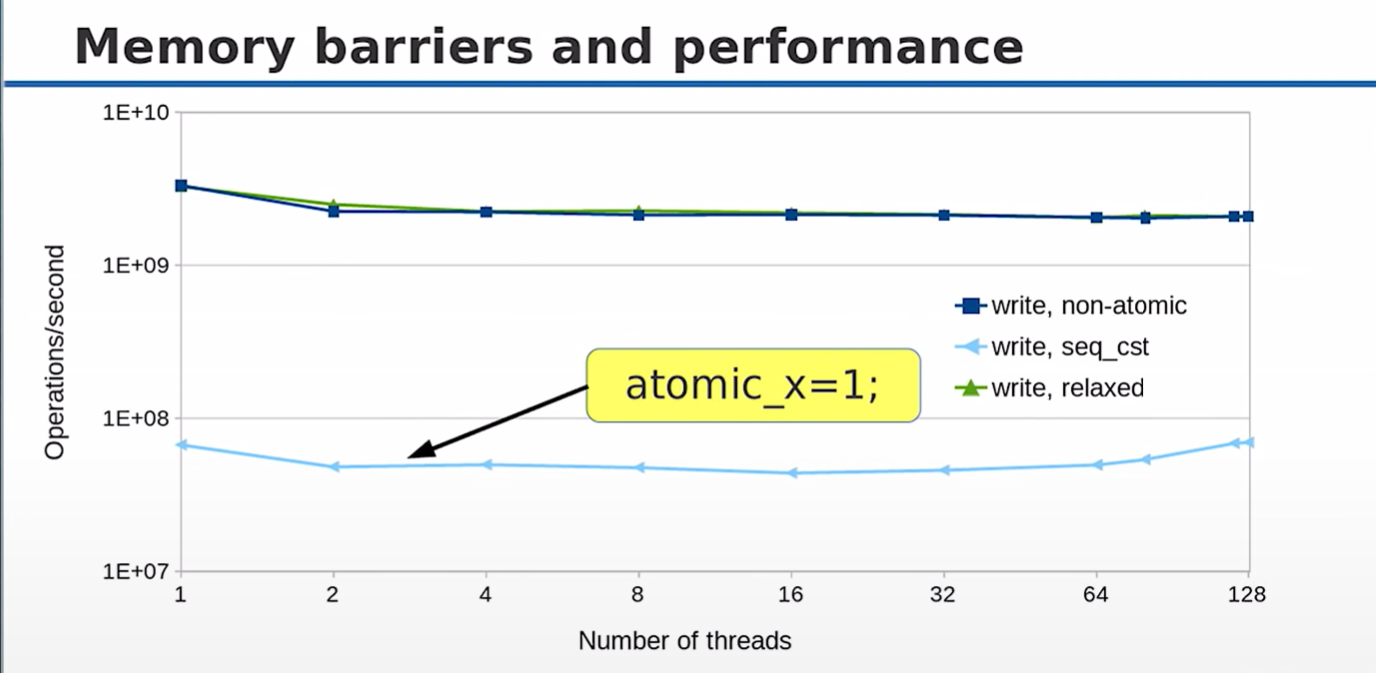 从上图中可以看出,
从上图中可以看出,memory_order_relaxed的写性能和 non-atomic几乎没有差别,而 seq_cst则要慢许多。
另一方面,使用不同等级的 memory order也能更好的表达你的代码的意图:
relaxed-model
最典型的例子就是一个线程安全的计数器。
std::atomic<size_t> counter;
counter.fetch_add(1, std::memory_order_relaxed);
你只是单纯的记录某件事情发生了几次。常用的还有智能指针中的引用计数的递增递减等
acuqire-release model
如果代码改成:counter.fetch_add(1, std::memory_order_release);那么这个counter就极有可能是某个数组的下标:你对某一个数组append了一个数,然后你才将其release(发布),告诉系统不允许将你对数组的append操作重排到counter增加之后;这样在其他线程中,其他线程就无法因为counter没更新而占有你已经append的位置。
acuqire-release 经常成对出现,因为他们共同表示了这样的一个模型:
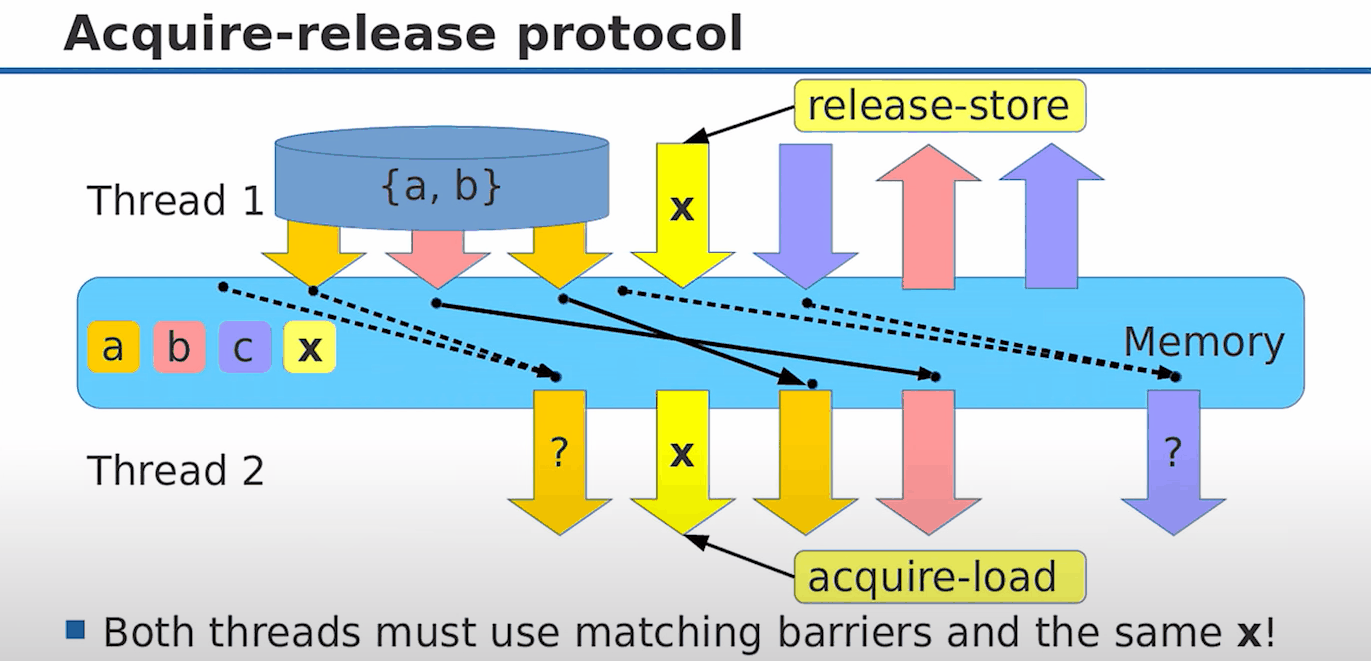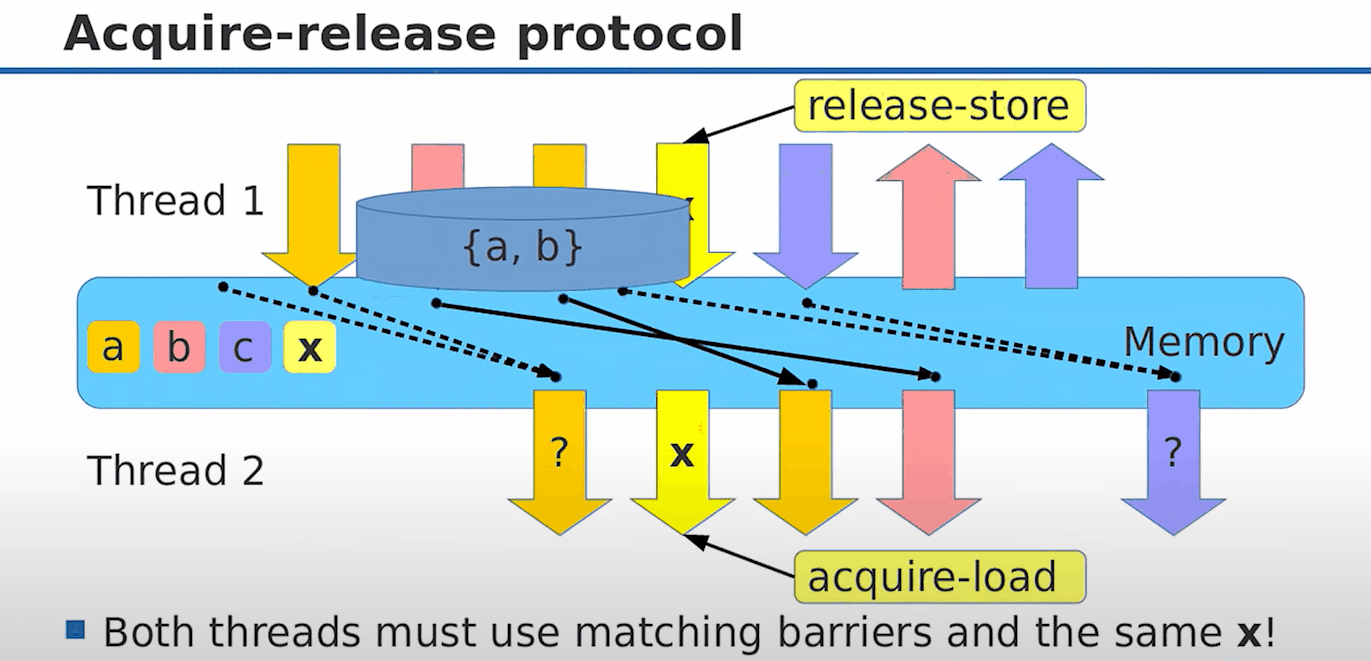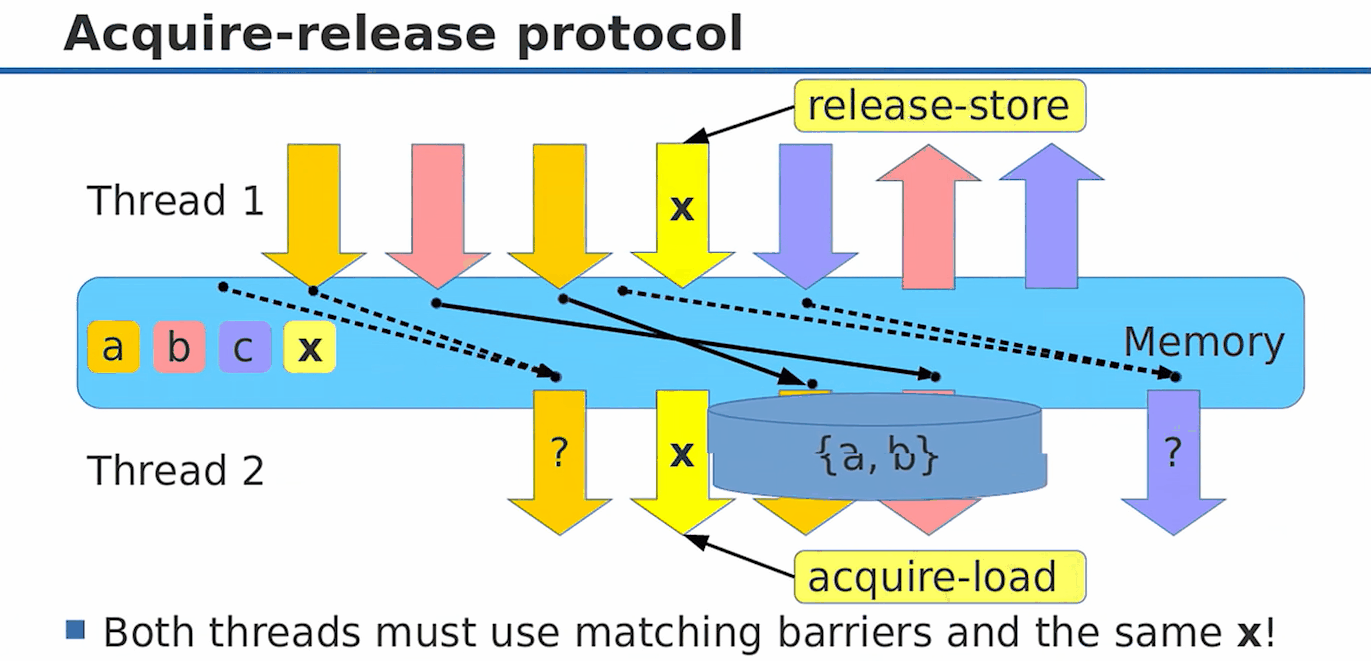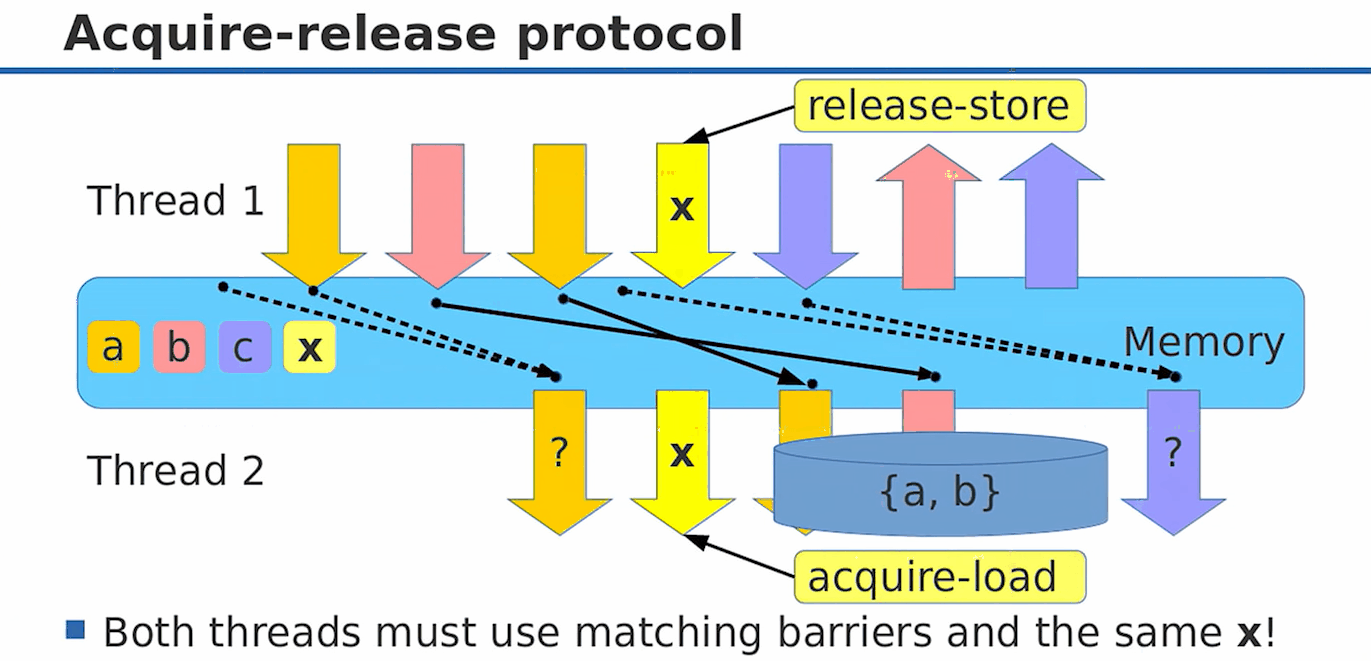
图中 {a, b}是我们需要在不同线程之间同步的值,那么线程1准备好 {a, b}后,release(发布) x,即 x.store(1, memory_order_release),这时我们保证了 {a, b}值的更新一定是 x = 1的时候可见的(因为{a, b}的更新操作不会被重排到x.store之后);那么在读线程,我们就可以根据 x 判断 {a, b}是否被更新:
while(x.load(memory_order_acquire) != 1)
;
[a', b'] = {a, b}; // acuire语义保证了这句话不会被重排到x.load之前
还有就是acq_sel_model了,这三种模型就是我们用std::atomic最常用的三种memory order.
其他
- 你可能已经注意到了,X86-TSO内存模型非常严格,它已经为我们提供了
- all load are acquire-loads, all stores are release-stores
- all read-modify-write operations are acquire-release
也就是说x86平台下不存在真正的memory-order-relexed
- 为什么
atomic<>比mutex更高效?最终不都是依赖于硬件提供的 barrier 以及 CAS, test and set等low level primitive吗?
- atomic 做的事情:原子指令修改内存,内存栅栏保障修改可见,必要时锁总线。
- mutex 大致做的事情:短暂原子 CAS(compare and set) 自旋如果未成功上锁,futex(&lock, FUTEX_WAIT… ) 退避进入阻塞等待直到 lock 值变化时唤醒。futex 在设计上期望做到如果无争用,则可以不进内核态,不进内核态的 fast path 的开销等价于 atomic 判断。内核里维护按地址维护一张 wait queue 的哈希表,发现锁变量值的变化(解锁)时,唤醒对应的 wait queue 中的一个 task。wait queue 这个哈希表的槽在更新时也会遭遇争用,这时继续通过 spin lock 保护。
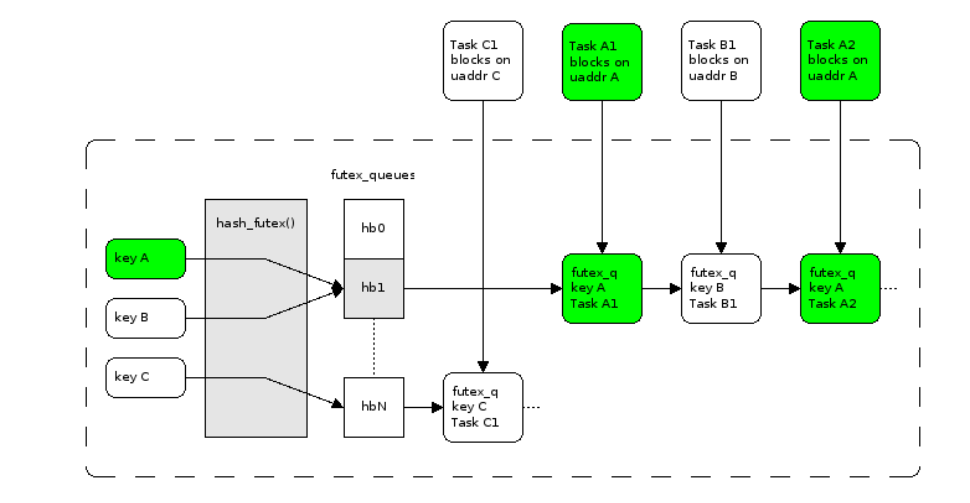
说白了就是mutex会陷入内核态(大部分情况下),而内核使用比较复杂的算法维护锁
std::atomic<>一定是无锁的吗?
wrong!
举个例子:
long x;
struct A {long x;}
struct B {long x; long y;}
struct C {long x; long y; long z;}
那么atomic
我们可以用std::atomic
C++17提供std::is_always_lock_free可以在编译器进行判断,如果为false不代表一定是 no lock_free的