本系列笔记主要参考了 “Programming massively parallel processors"这本书,以及网上相关资料;不会特别详细,当作个人整理的面经
CUDA软件架构
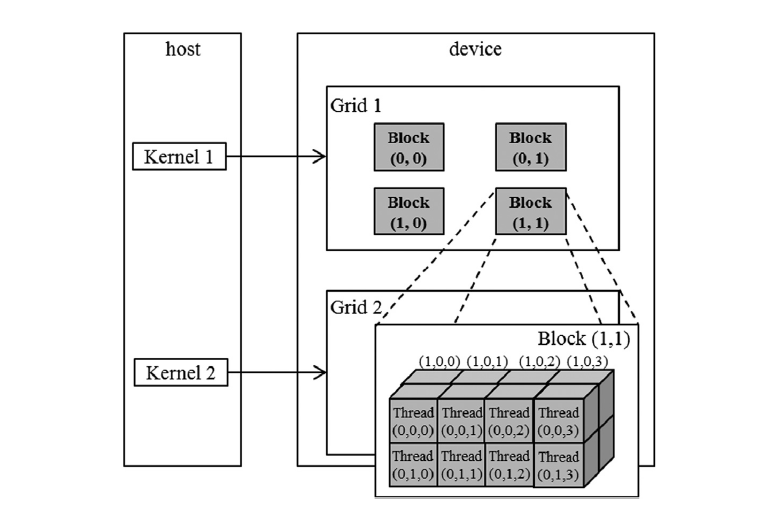
CUDA从软件层面上提供了三层结构包括grid, block和thread。每个kernal内启动的所有线程在一个grid内。启动kernel时指定«<dimGrid, dimBlock»>,都是一个dim3结构。
- gridDim的最大值范围: (x,y,z): (2^31 - 1, 65535, 65535)
- blockDim的最大值范围:(x,y,z): (1024, 1024, 64)
- 且还要同时满足:一个block内的threads数量不能超过1024(从kepler开始)。即:$ blockDim.x * blockDim.y * blockDim.z <= 1024 $
CUDA内存架构
| 变量声明 | 所在内存 | 作用域 | 生命周期 |
|---|---|---|---|
| kernel内除了array的变量 | register | thread | grid |
| kernel内的array 变量 | local | thread | grid |
__shared__ 修饰的kernel内的变量 |
shared | block | grid |
__device__ 修饰的全局变量 |
global | grid | application |
__device__ __constant__ 修饰的全局变量 |
constant | grid | application |
- 其中 寄存器是GPU上运行速度最快的内存空间,延迟为1个时钟周期。
- 接下来是共享内存,共享内存是GPU上可受用户控制的一级缓存 。共享内存类似于CPU的缓存,不过与CPU的缓存不同,GPU的共享内存可以有CUDA内核直接编程控制。延迟为1~32个时钟周期。
- local memory实际上就在global memory上,只是通过编译器处理成私有的、每个线程独立的一块内存区域。一般一个kernal内的数组会被处理成local memory。延迟和global memory类似。
- 还有texture memeory,但是和科学计算相关不大。
CUDA硬件结构
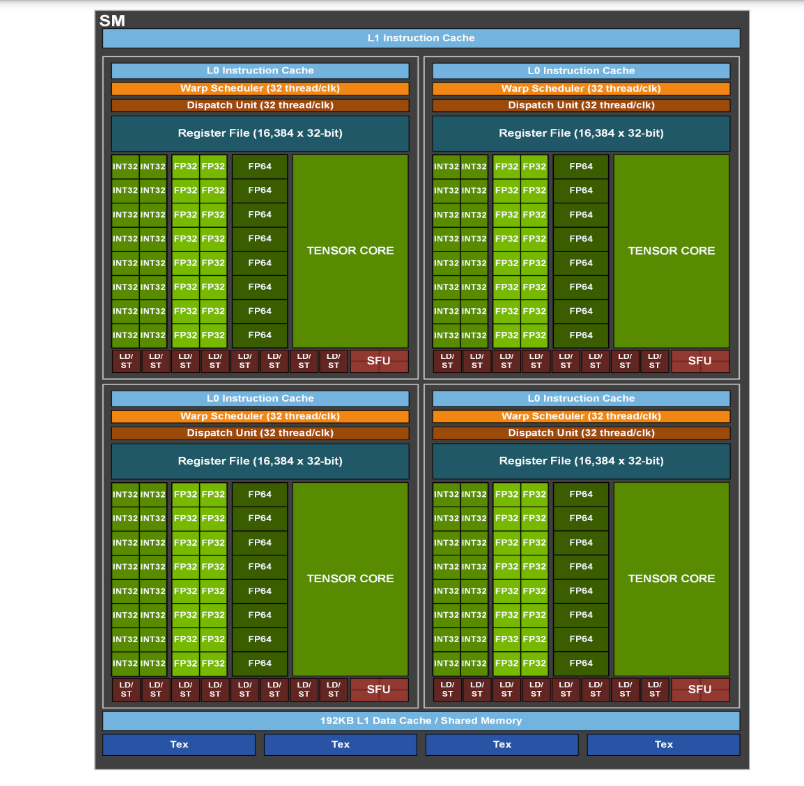
一个GPU可以看作是SM(streaming multiprocessor)的集合,每个SM包含多个SP(streaming processor,或者现在一般叫CUDA cores)。
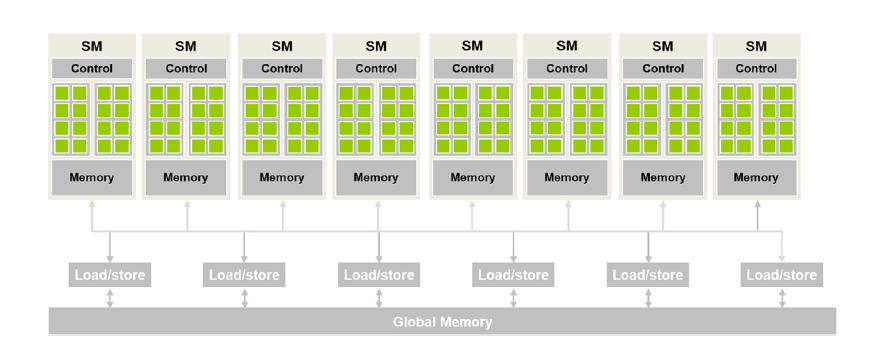
例如,在一个A100中,一共有108个SMs,每个SM有64个CUDA cores。
从软件调度上,一个grid对应整个GPU(多个SM),block对应SM,warp/thread级别对应一个CUDA core。
一个block内的threads一定被分配到同一个SM中,但有可能多个block都被分配到同一个SM中。(且可能同时分给一个SM超出硬件cores的线程,A100为例子 2048 threads == 32warps,只是真正同时运行某些warp,其余的可以用作hidding latency等)
每个SM上都有一个control,一个shared_memory。软件上可以通过__syncthreads()同步一个block内的所有线程。
SIMT(single instruction, multiple threads)
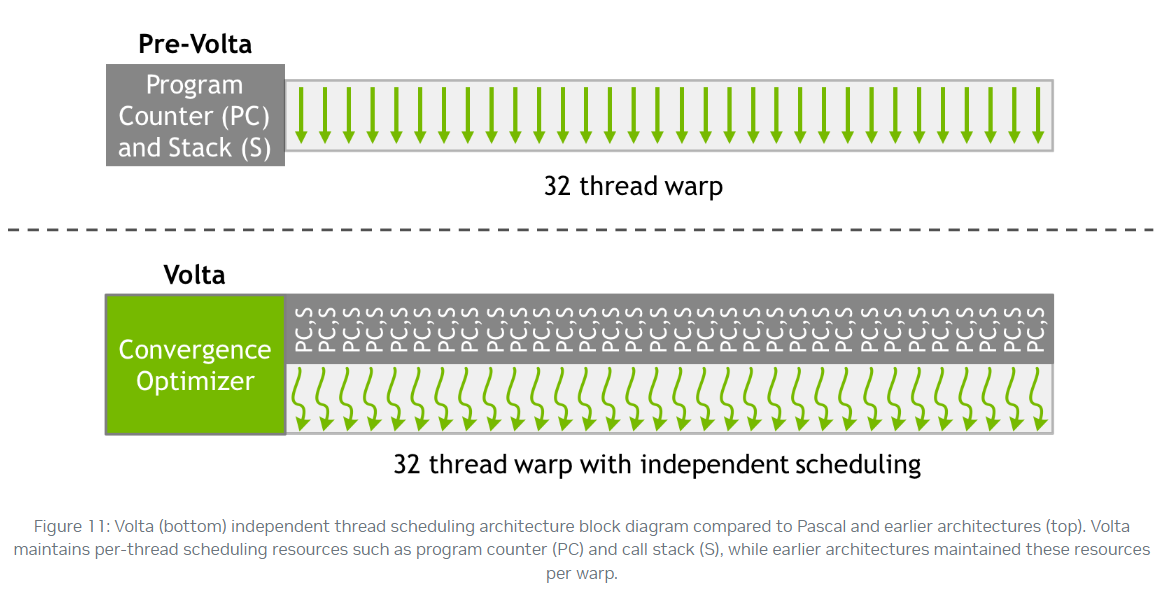
CUDA以 warp(线程束) 的形式组织线程,一般每32个线程组成一个warp,warp内的线程是SIMT(single instruction, multiple threads)的,Instructions are issued at the warp level.即一个warp内线程的指令的PC总是相同的 (实际上,Volta架构前,warp内的所有线程共享PC和stack;Volta架构后,warp内的不同线程有独立的PS,stack用于做Converge Optimizer)
如果我们创建的block线程数不是32的倍数会怎么样?会自动补到32的倍数。
其他
zero-overhead scheduling
CUDA中所说的零开销调度是什么意思呢?
一般来说,我们都会让一个SM上分配的warp数超出他能同时处理的warp数;这样,当有一个warp的指令是长延迟操作时(比如访问global memory),可以调度另一个不必等待的warp。当有足够多的warp时,硬件随时可以找到能够执行的warp,充分利用硬件资源。warp选取不会引入多余的执行时间,这被称为“零开销线程调度”。(这也是为什么GPUs不想CPUs一样,用大面积的芯片做缓存和分支预测) 还有一个原因在于,与CPU需要将寄存器存到内存中做上下文切换不同的是,GPU会将所有执行状态保存至寄存器上(每个SM内的寄存器数量非常庞大,见A100架构图),从而减小上下文切换(这里指切换warp开销)。
roofline model
Control divergence
function declarations
- global: CPU/GPU都可以call, 运行在GPU上
- device: 运行在GPU上,可以被其他__device__或__global__ call
- host: 运行在CPU上,可以被其他CPU call(可省略)
可以同时__host__ __device__修饰一个函数表示在CPU or GPU上运行
perf
平时如何进行kernel的优化,会用到哪些工具?
首先,要优化kernel函数需要先了解GPU硬件的构造。其次,需要熟悉常见的profiler工具,主要包括Nsight System和Nsight Compute。
在优化的手段和方向上主要关注几个点:
- 使用异步API:如cudaMemcpyAsync可让GPU操作与CPU操作并行,CPU忙完后调用cudaStreamSynchronize,cudaEventWait等操作等待GPU任务完成。
- 优化内存与显存传输效率
- 使用Pinned(page-locked) Memory提高传输速度
- 通过在不同的Stream里同时分别执行kernel调用及数据传输,使数据传输与运算并行。(注意default stream的坑)
- 尽量将小的数据在GPU端合成大块数据后传输
- 优化Kernel访存效率
- 提高Global Memory访存效率
- 对Global Memory的访存需要注意合并访存(coalesced )。
- warp的访存合并后,起始地址及访存大小对齐到32字节
- 尽量避免跨步访存
- CUDA 8.0及以上的设备可以通过编程控制L2的访存策略提高L2命中率。
- 提高Shared Memory的访存效率
- shared memory由32个bank组成
- 每个bank每时钟周期的带宽为4字节
- 连续的4字节单元映射到连续的bank。如0-3字节在bank0,4-7字节在bank1……字节128-131字节在bank0
- 若warp中不同的线程访问相同的bank,则会发生bank冲突(bank conflict),bank冲突时,warp的一条访存指令会被拆分为n条不冲突的访存请求,降低shared memory的有效带宽。所以需要尽量避免bank冲突。
- CUDA 11.0以上可以使用async-copy feature
- 提高Global Memory访存效率
一些并行算法
TODO: reduce, gemm, transpose, softmax, layernor
#define TILE_WIDTH 16
__global__ void matrixMulKernel(float* M, float* N, float* P, int Width) {
__shared__ float Mds[TILE_WIDTH][TILE_WIDTH];
__shared__ float Nds[TILE_WIDTH][TILE_WIDTH];
int bx = blockIdx.x, by = blockIdx.y;
int tx = threadIdx.x, ty = threadIdx.y;
int row = by * TILE_WIDTH + ty;
int col = bx * TILE_WIDTH + tx;
float value = 0.0f;
for (size_t i = 0; i < Width / TILE_WIDTH; i ++) {
Mds[ty][tx] = M[row * Width + i * TILE_WIDTH + tx];
Nds[ty][tx] = M[(i * TILE_WIDTH + ty) * Width + col];
__syncthreads();
for (size_t k = 0; k < TILE_WIDTH; k ++) {
value += Mds[ty][k] * Nds[k][tx];
}
__syncthreads();
}
P[row * Width + col] = value;
}