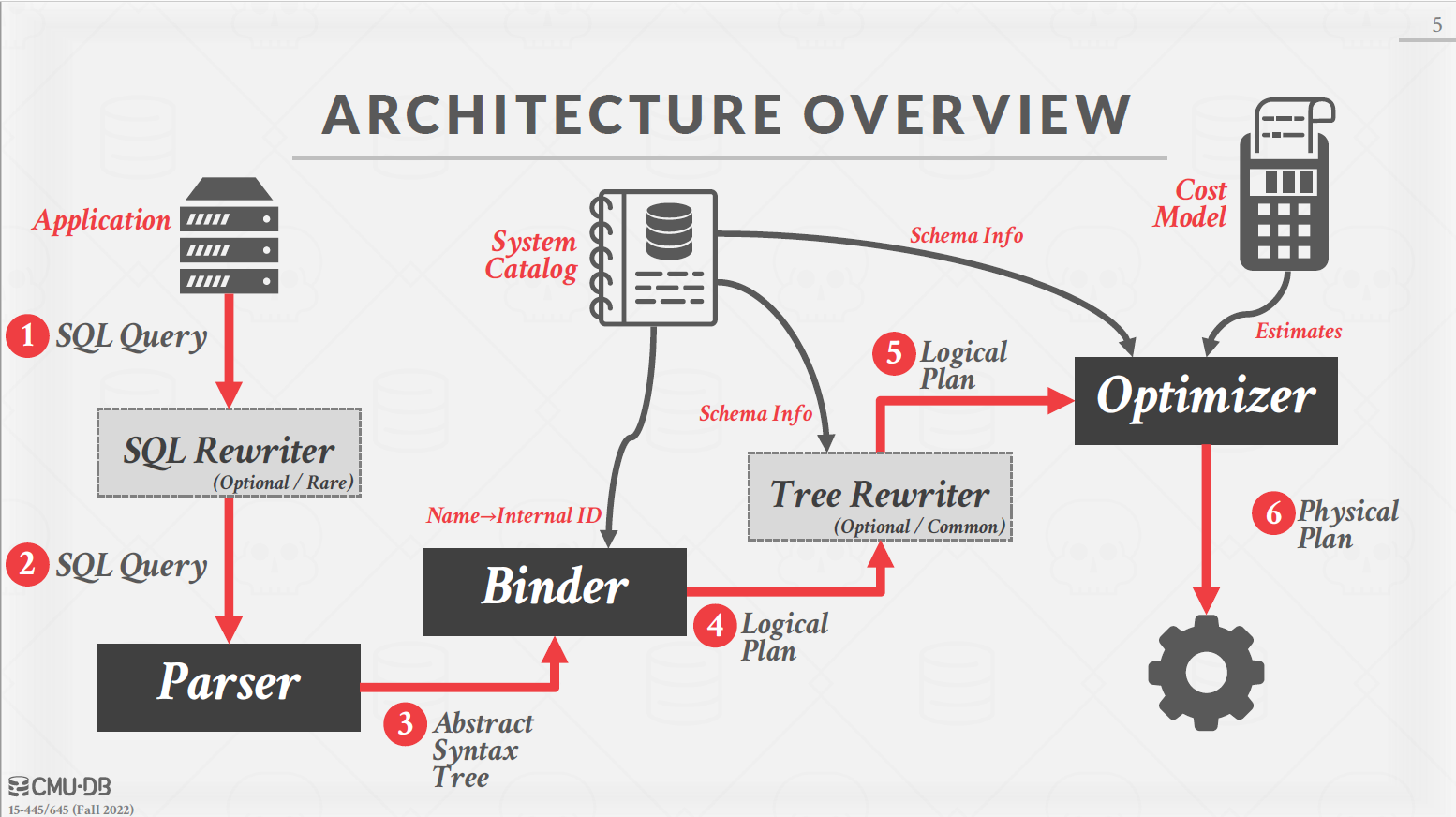
C++ CRTP
原先只是了解这个名词,想着C++20后静态多态直接用 concept来实现就好了就没细看,没必要整这些模板元编程的奇技淫巧。没想到面试某量化C++开发的时候被狠狠拷打……. CRTP (curiously recurring template pattern) 一般认为,CRTP可以用来实现静态多态 template <typename T> class Base { void func() { static_cast<T*>(this)->funcImpl(); } }; class Derived : public Base<Derived> { void funcImpl() { // do works here } }; 通过CRTP可以使得类具有类似于虚函数的效果,同时又没有虚函数调用时的开销(虚函数调用需要通过虚函数指针查找虚函数表进行调用),同时类的对象的体积相比使用虚函数也会减少(不需要存储虚函数指针),但是缺点是无法动态绑定,感觉有点过于鸡肋。 有什么用呢?可以用来向纯虚类一样做接口:(以下类似的代码在大量数学库中出现) template <typename ChildType> struct VectorBase { ChildType &underlying() { return static_cast<ChildType &>(*this); } inline ChildType &operator+=(const ChildType &rhs) { this->underlying() = this->underlying() + rhs; return this->underlying(); } }; struct Vec3f : public VectorBase<Vec3f> { float x{}, y{}, z{}; Vec3f() = default; Vec3f(float x, float y, float z) : x(x), y(y), z(z) {} }; inline Vec3f operator+(const Vec3f &lhs, const Vec3f &rhs) { Vec3f result; result.x = lhs.x + rhs.x; result.y = lhs.y + rhs.y; result.z = lhs.z + rhs.z; return result; } 定义好VectorBase后,Vec3f, Vec4f等直接实现接口就好。相比虚函数的形式,在空间和runtime都有优势。 ...